Last updated: June 17, 2023 11:22 AM (All times are UTC.)
June 01, 2030
Recent & Upcoming Talks by John Sear (@DiscoStu_UK)
June 16, 2023
Don’t ask me later by James Nutt (@zerosumjames)
This is just a minor vent, but why are notification choices so often just:
- Yes
- Not right now, but please keep asking me
“No, please don’t ask again” is a frustratingly rare option. I know, I know. Notifications drive engagement and you’re incentivised to keep pestering me until I give in. I empathise with your situation.
However, I do wish you’d stop.
June 09, 2023
Reading List 305 by Bruce Lawson (@brucel)
- FCC Requires Video Conferencing Accessibility & Proposes ASL Support – yay.
- A Heart-felt Apology and a Chance to Start Again from AccessiBe, overlay maker. Hurray!
- Meanwhile, AudioEye Is Suing Me – totally definitely NOT an overlay maker, AudioEye, is suing Adrian Roselli. Boooo.
- Overlays – Web Accessibility for Business Owners Dan Payne has a soothing voice and doesn’t swear or thump the table when explaining why accessibility overlays aren’t the panacea they often pretend to be.
- Getting started with View Transitions on multi-page apps – “It took less than an hour to do, requires zero JavaScript, and two lines of CSS. I’m pleased with the results”. Progressive enhancement with declarative code – real web developers love to see it!
- Amazon Luna will drop Windows and Mac apps as it ‘doubles down’ on web app – “We saw customers were spending significantly more time playing games on Luna using their web browsers than on native PC and Mac apps. When we see customers love something, we double down. We optimized the web browser experience with the full features and capabilities offered in Luna’s native desktop apps”
- Talking of which, News from WWDC23: WebKit Features in Safari 17 beta – “Web apps are coming to Mac”. No news of the View Transitions spec or meaningful browser choice on iThings.
- Web Apps on macOS Sonoma 14 Beta – some tech notes by Thomas Steiner
- A series of hands‐on guides to assitive technology and accessibility testing
- 11 HTML best practices for login & sign-up forms – includes the evergreen “All clickables should use button or a, not div or span”. Sadly, there are people allowed within 14 miles of the front end who still need to be told this.
- Fieldsets, Legends and Screen Readers again – Steve “Chuckles” Faulkner updated his 15 year old blog post.
- Semantics and the popover attribute: what to use when? – Hidde on the new HTML attribute named after one of my favourite Soviet constructivist artists, Lyubov Sergeyevna Popova (Любо́вь Серге́евна Попо́ва). I like things like popover, dialog, details and summary – they’re common pains for people who use keyboards or assistive tech, and have often prompted “Full-stack” developers (as opposed to Web Developers) to drag in libraries and frameworks in order to implement them.
- The Industrial Hammer Complex – What we actually have is an industrial complex bent on manufacturing only hammers, committed to convincing you that only nails exist, and motivated to sell you a lifetime hammer subscription!” I recently investigated a page that had different spinners for each block (header, footer, nav – because MiCrOsErViCeS!!!). It preloaded loads of WebRTC framework, OAuth shit (because SPAs are gReAT!!) and an SVG logo (that contained a 1.6MB bitmap). All this, to show a login form, which took 45 secs over 3G.
- Boring Report is an app that aims to remove sensationalism from the news. In today’s world, catchy headlines and articles often distract readers from the actual facts and relevant information.” Using AI, Boring Report processes exciting news articles and transforms them so readers focus on the essential details and minimises the impact of sensationalism.
- Google’s Open Source AI Tool Is a Major Step Forward for Accessibility in Gaming – “Project Gameface uses your head and facial movements to control a mouse cursor.”
- US Agency Releases Free Stock Photos of People With Disabilities
- When digital nomads come to town -“Cities from Canggu to Medellín are welcoming tech workers, but locals complain they’re being priced out. The digital nomads’ visits are transitory, but they leave neighborhoods permanently transformed. Today, there are streets in Medellín, as in Mexico City or Canggu, that look more like Bushwick — where English is more common than the local language. Building exteriors retain their historic character, but interiors converge to a sterile homogeneity of hotdesking, free charging outlets, affordable coffee, and Wi-Fi with purchase.”
- Rishi Sunak alt text tweet criticised for misusing accessibility feature – #AltTextGate
- Kenny Log In – “GENERATE A SECURE PASSWORD FROM THE LYRICS OF AMERICA’S GREATEST SINGER SONGWRITER”
June 05, 2023
CENTRAL BIRMINGHAM 2040: Shaping Our City Together (unofficial accessible version) by Bruce Lawson (@brucel)
My chum Stuart is a civic-minded sort of chap, so he drew my attention to Birmingham’s strategic plan for 2040. There’s a lot to be commended in the plan’s main aims (although it’s a little light on detail, but that’s a ‘strategy’, I guess). However, we noticed that it was hard to find on the Council website (subsequently rectified and linked from the cited page).
I was also a bit grumpy that it is circulated as a 43 MB PDF document, which is a massive download, especially for poorer members of the population who are more likely to be using phones than a desktop computer (PDF, lol), and more likely to have pay-as-you-go data plans (PDF, ROFL) which are more expensive per megabyte than contracts.
PDFs are designed for print so don’t resize for phone screens, requiring tedious horizontal scrolling–potentially a huge barrier for some people with disabilities, and a massive pain in the arse for everyone. For people who don’t read English well, PDFs are harder for translation software to access, so I’ve made an accessible HTML version of the Shaping Our City Together document.
I haven’t included the images, which are lovely but heavy, for two reasons. The first is that many are created by someone called Tim Cornbill and I don’t want to infringe their copyright. Some of the illustrations are captioned “This concept image is an artist’s impression to stimulate discussion, it does not represent a fixed proposal or plan”, so I decided they were not content but presentational and therefore unnecessary.
Talking of copyright, the document is apparently Crown Copyright. Why? I helped pay for it with my Council tax. Furthermore, I am warned that “Unauthorised reproduction infringes Crown Copyright and may lead to prosecution or civil proceedings”, so if Birmingham Council want me to take this down, I will. But given that the report talks glowingly of the contribution made to the city’s history by The Poors and The Foreigns, it seems a bit remiss to have excluded them from a consultation about the City’s future.
Because I am not a designer, the page is lightly laid out with Alvaro Montoro’s “Almond CSS” stylesheet. I am, however, an accessibility consultant. The Council could hire me to sort out more of their documents (so could you!).
May 31, 2023
State of the Browser 2022 video: IE6 – RIP or BRB by Bruce Lawson (@brucel)
Here’s the video of my talk.
The slides are available.
My White Whale by Luke Lanchester (@Dachande663)
I have a project, codenamed Ox currently, that has been consuming me for the past seven years.
It’s not a difficult project, not when I know what I want out of it. Like dealing with any client though, the hard part is knowing what I want out of it.
It’s supposed to be a… space, for me. Track scrobbles, games played, photos taken and where, people, friends, control lights, last forever, be available everywhere but only locally.
I have gone through iteration after iteration, oftentimes using it as an excuse to spelunk into some deep dark corner of technology to my lizard brain.
- Static files with a CLI tool to parse and extract
- Golang, rust, electron desktop GUIs
- SQLite data replicated via CRDTs
- Docker, firecracker, wasm engines to execute simple scripts
- A simple PHP & MySQL website
Everytime, I find a reason not to continue. I am on version 44. I passed the meaning of life and still can’t sleep because I think of another angle.
I know the solution is to write a spec req doc.
I know the solution is to split this out into tool A, tool B, tool C.
I know the solution is to use off-the-shelf tools.
But I don’t know.
May 25, 2023
Every bunch of tech hippies needs a touch of Bruce™ by Bruce Lawson (@brucel)
Since my last employer decided just before Xmas that it didn’t need an accessibility team any more, I’ve been sporadically applying for jobs, between some freelance work and finishing the second album by the cruellest months (give it a listen while you read on!).
Two days ago I was lucky enough to receive two rejection letters from acronym-named corporations. Both were received only a couple of working hours after I eventually hit submit in their confusing (and barely-accessible) third-party job application portals, which makes me suspicious of their claims to have “carefully considered” my application. One rejection, I suspect, was because I’d put too large a figure in the ‘expected salary’ box; how am I supposed to know, when the advertised salary is “competitive”? In retrospect, I should have just said typed “competitive” into the box.
The second rejection reason is a little harder to discern. As I exceeded all the criteria, I suspect admitting to the crimes of being over 50 and mildly disabled worked against me. But I’ll never know; no feedback was offered, and both auto-generated emails came from a no-reply email address. (Both orgs make a big deal on their sites about valuing people etc. Weird.)
Apart from annoyance at the time I wasted (I have blogposts to write, and songs to record!) I remembered that I hate acronymy corporate jobs anyway. So, if you need someone on a short-term/ part-time (or long-term) basis to help educate your team in accessibility, evaluate your project and suggest improvements, give me a yell. In answer to a question on LinkTin, I’ve listed the accessibility and web standards services I offer.
Mates’ Rates if you’re a non-acronymy small Corp who are actively trying to make the world better rather than merely maximise shareholder value. Remember: every bunch of tech hippies needs a touch of Bruce .
.
May 15, 2023
I’ve released my second album “High Priestess’ Songs” by the cruellest months, the name I’ve given to the loose collaboration between me and assorted friends to record and release my songs.
High Priestess' Songs by the cruellest months
Please, give it a listen and consider buying it for £5 so I can buy a pint while I’m looking for a new job.
(Last Updated on )
May 12, 2023
Reading List 304 by Bruce Lawson (@brucel)
- The Fugu project: priorities, Mozilla and Apple, support realms, Web vs native, and future plans – Vadim and I interrogate Thomas Steiner on Te F-word
- Scoped CSS is back (in Chromium, behind a flag). Great news for ending CSS-in-JS abominations.
- Add the WAI-ARIA Usage bookmarklet to evaluate document conformance requirements for use of ARIA attributes in HTML and allowed ARIA roles, states, and properties.
- Meeting WCAG Level AAA – Pattypoo cascades his wisdom
- The ongoing defence of frontend as a full-time job
– “You can hire frontend developers to build your product, or make it happen somehow and later on hire performance and accessibility consultants to fix what doesn’t work properly.” – @codepo8 on why “frontend developer” is a real, and vital, specialism. - Scaling up the Prime Video audio/video monitoring service and reducing costs by 90% – The move from a distributed microservices architecture to a monolith application helped achieve higher scale, resilience, and reduce costs.
- How to use AI to do practical stuff: A new guide – “People often ask me how to use AI. Here’s an overview with lots of links.”
- Small Penises and Fast Cars: Evidence for a Psychological Link – “We found that males, and males over 30 in particular, rated sports cars as more desirable when they were made to feel that they had a small penis”. Thanks, Science!
April 21, 2023
Response Time by Luke Lanchester (@Dachande663)
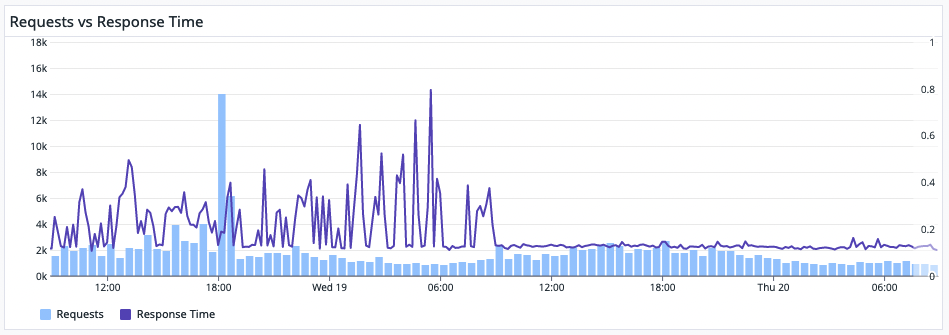
Feels good.
April 14, 2023
Reading List 303 by Bruce Lawson (@brucel)
Some interesting stuff I’ve been reading lately. Don’t forget, I’m available for part-time accessibility / web standards consultancy to help any organisation that isn’t making the world worse (and better rates for orgs that are actively trying to make the world better).
- Safari releases are development hell – “We make the browser-based game creation app Construct … I wanted to share our experience so customers, developers, regulators, and Apple themselves can see what we go through with what is supposed to be a routine Safari release.”
- Modern Font Stacks – “System font stack CSS organized by typeface classification for every modern OS. The fastest fonts available. No downloading, no layout shifts, no flashes — just instant renders.”
- The Most Dangerous Codec in the World: Finding and Exploiting Vulnerabilities in H.264 Decoders – head-hurtingly detailed PDF.
- People do use Add to Home Screen – Mozilla did some user testing. “four of ten people in a user test – what does that tell us? It tells us that it’s something that at least some regular people do and that it’s not a hidden power user feature”.
- The Automation Charade The rise of the robots has been greatly exaggerated. Whose interests does that serve?
- AI and the American Smile – How AI misrepresents culture through a facial expression
- Floor796 “is an ever-expanding animation scene showing the life of the 796th floor of the huge space station! The goal of the project is to create as huge animation as possible, with many references to movies, games, anime and memes”. Drag around and click to find out more.
April 06, 2023
Sonnet 2 by James Nutt (@zerosumjames)
Through PHP and Java, skills were born
But settled now on Ruby, life’s true love.
To not look down on past projects with scorn
But elevate my craft and look above.
O, Ruby! A Bridgetown site could not hold
My love for thee, inside of markdown lines.
A fresh Rails application could not load.
Your name in the Gemfile - a thousand times.
Metaprogramming a new DSL
With nested blocks and elegant syntax
Cannot capture the rush of my heart’s swell
For all the language holds, still my tongue lacks.
Ruby 3, YJIT too, and also minitest
Static sites and CLIs! Ruby, you’re the best.
April 04, 2023
Dungeons & Dragons: Honour Among Thieves, a review by Stuart Langridge (@sil)
So, Dungeons & Dragons: Honour Among Thieves, which I have just watched. I have some thoughts. Spoilers from here on out!

Up front I shall say: that was OK. Not amazing, but not bad either. It could have been cringy, or worthy, and it was not. It struck a reasonable balance between being overly puffed up with a sense of epic self-importance (which it avoided) and being campy and ridiculous and mocking all of us who are invested in the game (which it also avoided). So, a tentative thumbs-up, I suppose. That’s the headline review.
But there is more to be considered in the movie. I do rather like that for those of us who play D&D, pretty much everything in the film was recognisable as an actual rules-compliant thing, without making a big deal about it. I’m sure there are rules lawyers quibbling about the detail (“blah blah wildshape into an owlbear”, “blah blah if she can cast time stop why does she need some crap adventurers to help”) but that’s all fine. It’s a film, not a rulebook.
I liked how Honour Among Thieves is recognisably using canon from an existing D&D land, Faerûn, but without making it important; someone who doesn’t know this stuff will happily pass over the names of Szass Tam or Neverwinter or Elminster or Mordenkainen as irrelevant world-building, but that’s in there for those of us who know those names. It’s the good sort of fanservice; the sort that doesn’t ruin things if you’re not a fan.
(Side notes: Simon is an Aumar? And more importantly, he’s Simon the Sorcerer? Is that a sly reference to the Simon the Sorcerer? Nice, if so. Also, I’m sure there are one billion little references that I didn’t catch but might on a second or third or tenth viewing, and also sure that there are one billion web pages categorising them all in exhaustive detail. I liked the different forms of Bigby’s Hand. But what happened to the random in the gelatinous cube?)
And Chris Pine is nowhere near as funny as he thinks he is. Admittedly, he’s playing a character, and obviously Edgin the character’s vibe is that Edgin is not as funny as he thinks he is, but even given that, it felt like half the jokes were delivered badly and flatly. Marvel films get the comedy right; this film seemed a bit mocking of the concept, and didn’t work for me at all.
I was a bit disappointed in the story in Honour Among Thieves, though. The characters are shallow, as is the tale; there’s barely any emotional investment in any of it. We’re supposed, presumably, to identify with Simon’s struggles to attune to the helmet and root for him, or with the unexpectedness of Holga’s death and Edgin and Kira’s emotions, but… I didn’t. None of it was developed enough; none of it made me feel for the characters and empathise with them. (OK, small tear at Holga’s death scene. But I’m easily emotionally manipulated by films. No problem with that.) Similarly, I was a bit annoyed at how flat and undeveloped the characters were at first; the paladin Xenk delivering the line about Edgin re-becoming a Harper with zero gravitas, and the return of the money to the people being nowhere near as epically presented as it could have been.
But then I started thinking, and I realised… this is a D&D campaign!
That’s not a complaint at all. The film is very much like an actual D&D game! When playing, we do all strive for epic moves and fail to deliver them with the gravitas that a film would, because we’re not pro actors. NPCs do give up the info you want after unrealistically brief persuasion, because we want to get through that quick and we rolled an 18. The plans are half-baked but with brilliant ideas (the portal painting was great). That’s D&D! For real!
You know how when someone else is describing a fun #dnd game and the story doesn’t resonate all that strongly with you? This is partially because the person telling you is generally not an expert storyteller, but mostly because you weren’t there. You didn’t experience it happening, so you missed the good bits. The jokes, the small epic moments, the drama, the bombast.
That’s what D&D: Honour Among Thieves is. It’s someone telling you about their D&D campaign.
It’s possible to rise above this, if you want to and you’re really good. Dragonlance is someone telling you about their D&D campaign, for example. Critical Role can pull off the epic and the tragic and the hilarious in ways that fall flat when others try (because they’re all very good actors with infinite charisma). But I think it’s OK to not necessarily try for that. Our games are fun, even when not as dramatic or funny as films. Honour Among Thieves is the same.
I don’t know if there’s a market for more. I don’t know how many people want to hear a secondhand story about someone else’s D&D campaign that cost $150m. This is why I only gave it a tentative thumbs-up. But… I believe that the film-makers’ attempt to make Honour Among Thieves be like actual D&D is deliberate, and I admire that.
This game of ours is epic and silly and amateurish and glorious all at once, and I’m happy with that. And with a film that reflects it.
March 28, 2023
“Whose web is it, anyway?” My axe-con talk by Bruce Lawson (@brucel)
The nice people at Deque systems asked me to kick off the developer track of their Axe Conference 2023. You can view the design glory of my slides (and download the PDF for links etc). Here’s the subtitled video.
(We’ll ignore the false accusation in the closed captions that I was speaking *American* English.)
I generated the transcript using the jaw-droppingly accurate open-source Whisper AI. Eric Meyer has instructions on installing it from the command line. Mac users can buy a lifetime of updates to MacWhisper for less than £20, which I’ve switched to because the UI is better for checking, correcting and exporting (un-timestamped) transcripts like we use for our F-word podcast (full of technical jargon, with a Englishman, a Russian and even an American speaking English with their own accents). This is what Machine Learning is great for: doing mundane tasks fast and better, not pirating other people’s art to produce weird uncanny valley imagery. I’m happy to welcome my robot overlords if they do drudgery for me.
March 27, 2023
Making Things by Luke Lanchester (@Dachande663)
I have hit a block. Not a writing block, not per-se. More of a mental staircase of ascending excuses. I just can’t make things anymore for myself.
I used to love bashing out small scripts in various languages. Sometimes to scratch an itch in learning something new. Sometimes just to fix a pain point elsewhere. These scripts were… horrible. But they ran. They worked. Often they didn’t have tests, but you could grok the entire codebase in two scrolls of any IDE.
Nowadays, I do most of my day-to-day work been paid to write large systems. Enterprise auth, backend orchestration. Everything is specced, tested, deployed and versioned. This gives me great confidence in what we’re shipping.
But then, these two worlds collide and I end up… doing nothing.
I wanted to make a tiny photo library script to just read some shares off of a NAS and show me pictures taken on that day in years gone by. But all of a sudden I was setting up Dockerfiles and dependencies, working out if VIPS was better that imagemagick.
I couldn’t just query a DB, I had to design a schema with type-hinting and support for migrations later on, and what if I wanted to share an image outside the network or $DIETY forbid, share the application with others.
Where do I land on the spectrum of a one-file Python or PHP or whatever script that just scrapes a glob exec command’s output, and setting up a k3s cluster with a rust-build toolchain that analyzes everything and has full support for expanding into anything and everything.
I want to solve problems. That’s why I became a dev. Not to become an architecture astronaut or sit infront of a terminal window paralysed about making the wrong choice.
Frog Porridge by James Nutt (@zerosumjames)
1.312723258290198, 103.87928286812601
There’s a productivity technique called “Eat the Frog.” As I understand it, the idea is this: every day, you start with the most challenging task on your list (the frog) and you do that first (eat it). This feeling of accomplishment will either carry you breezily through several more tasks, or you take the rest of the day off, but can rest happily in the knowledge that you’ve got at least one big thing less to worry about. It sounds like a sensible system. If the idea behind “eat the frog” is based on the idea that frogs are difficult or unpleasant to eat, however, then it’s time for it to be renamed.
On a street corner in Singapore, a tornado of staff ferries bowls of frog porridge and an assortment of other dishes to small plastic tables. An open kitchen and relatively bare surroundings, the overall impression is less of a restaurant, but rather buying food directly from the foreman of a busy factory floor. A woman with carefully manicured and bejewelled nails, in contrast to almost everything else within eyesight, takes our money and seems to telepathically transmit our order to the small army of cooks in the background, who all the while have been stirring and ladling.
With a few particular exceptions, I’ll try to eat almost anything once. Most things I’ll eat as often as I can get my hands on. Still, I’d never eaten frog porridge before and it’s normal to be a little apprehensive about the unknown. Will it be slimy or crispy? Do frogs… have bones? Will they be diced, or a sort of paste, or a complete set of legs, lifted directly from a children’s comic book? In other words, will it be recognisably froggy?
We ordered one bowl of porridge with three spicy frogs to go, killed twenty minutes wandering the neighbourhood, circled back, and picked them up. More or less what one might expect. Small chunks of soft and slightly chewy meat in an extremely rich, salty, dark brown sauce. Visibly meaty, but you’d be hard pressed to say which animal just by looking. All sat atop a delicious bowl of rice porridge.
Between the unflagging love for aircon and what struck me as uncharacteristically cold weather, I’d somehow spent most of the trip being cold. The weather app was telling me it was 28°C, which I doubted. Further down the page, it tells me that it “feels like 32.” The app, perhaps as surprised as I am at the cold, was doing its best to deny reality. I thought about the jacket that I’d left at home, a puffy bomber that would probably shoot me from too cold straight to being too warm. I’ve managed to cunningly ensure that I can be uncomfortable in every situation. Busines as usual. At least the porridge was good.
March 24, 2023
Reading List 302 by Bruce Lawson (@brucel)
- Checking out and building Chromium for iOS – yup, you heard that right: real Chromium on iOS.
- The new HTML <search> element means a native way to let Assistive Tech what something is without
role="Search" - How Shadow DOM and accessibility are in conflict by Alice Boxhall
- Unicode Roman Numerals and Screen Readers by Uncle Tezza
- Building an Accessibility Library Give UX designers the tools to build products everyone can use.
- GitHub Copilot investigation – “We’re investigating a potential lawsuit against GitHub Copilot for violating its legal duties to open-source authors and end users”
- Building Accessible React Applications: Best Practices for Senior Engineers – this is all good advice. But why best practices for *Senior* engineers? If you aren’t doing these things, you ain’t an engineer.
- Why is Apple making big improvements to web apps for iPhone? Apple seems to be working on features that make web applications a little more like native apps. Now, why would Apple want to do that?
- What WCAG 2.2 Means for Native Mobile Accessibility
- Learn Privacy – A course to help you build more privacy-preserving websites, by Stuart Langridge
- Dumb Password Rules – A compilation of 292 sites with dumb password rules.
- The Jennifer Mills News – I love this: for the last 20 years, Jennifer Mills has been reporting the mundane things in her life in the style of an old-time regional newspaper, every Friday
March 07, 2023
Diagnosing “early termination of worker” errors by James Nutt (@zerosumjames)
You might be trying to start your Rails server and getting something like the following, with no accompanying stack trace to tell you exactly what it is that’s gone wrong.
[10] Early termination of worker
[8] Early termination of worker
This is a note-to-self after encountering this when trying to upgrade a Rails app from Ruby 2.7 to 3.2. What helped me was a comment from this Stack Overflow post.
If rails s or bundle exec puma is telling you the workers are being terminated but not telling you why, try:
rackup config.ru
February 17, 2023
Reading List 301 by Bruce Lawson (@brucel)
- Link o’The Week: The Market for Lemons – Big Al Russell on how managers and developers have come to believe -against all evidence- that massive frameworks are better for making web things.
- A Historical Reference of React Criticism Over 8 years worth of people pointing out the performance calamity that is React, curated by Zach Leatherman
- Why I’m not the biggest fan of Single Page Applications – to do them well you have to reimplement lots of things browsers do by defaults in normal web pages. Hopefully when the View Transitions API comes to multi page apps we’ll square the circle
- Container queries land in stable browsers – a short tutorial by Una Kravets
- I just wanted to buy pants How excessive JavaScript is costing you money
- The case for frameworks – Laurie Voss makes the case for React. It’s well-argued, but I’m unconvinced everybody has considered the downsides and balanced the risks. Everyone I consult with seems shocked at the performance and accessibility nasties of many of the popular frameworks.
- CSS lazy loading is broken in Safari by Vadim Makeev
- The (extremely) loud minority – Andy Bell, a Northerner, gets righteously grumpy again. I’m worried about the lad’s blood pressure, to be honest. Have a pontefract cake, mate, and take the weight of the world off your whippet.
- Nintendo to increase wages 10% despite lowered forecast – “It’s important for our long-term growth to secure our workforce” president Shuntaro Furukawa said
- Microsoft to phase out Internet Explorer with newer Edge browser – An update will begin to replace its 27-year-old predecessor from Tuesday. Farewell, old frenemy.
February 13, 2023
Clog by Luke Lanchester (@Dachande663)
There was recently a discussion on Hacker News around application logging on a budget. At work I’ve been trying to keep things lean, not to the point of absurdity, but also not using a $100 or $1000/month setup, when a $10 one will suffice for now. We settled on a homegrown Clickhouse + PHP solution that has performed admirably for two years now. Like everything, this is all about tradeoffs, so here’s a top-level breakdown of how Clog (Clickhouse + Log) works.
Creation
We have one main app and several smaller apps (you might call them microservices) spread across a few Digital Ocean instances. These generate logs from requests, queries performed, exceptions encountered, remote service calls etc. We use monolog in PHP and just a standard file writer elsehwere to write new-line delimited JSON to log files.
In this way, there is no dependency between applications and the final logs. Everything that follows could fail, and the apps are still generating logs ready for later collection (or recollection).
Collection
On each server, we run a copy of filebeat. I love this little thing. One binary, a basic YAML file, and we have something that watches our log files, adds a few bits of extra data (the app, host, environment etc), and then pushes each line into a redis queue. This way our central logging instance doesn’t need to have any knowledge of each of the instances which can come and go.
(Weirdly, filebeat is part of elastic so can be used as part of your normal ELK stack, meaning if we wanted to change systems later, we have a natural inflection point.)
There’s definitely bits we could change here. Checking queue length, managing backpressue, etc. But do you know what? In 24 months of running this in production, ingesting between 750K to 1M logs a day, none of that has actually been a problem. Will it be a problem when we hit 10M or 100M logs a day? Sure. But then we have a different set of resources to hand.
Ingesting
We now have a redis queue with a queue of JSON log lines. Originally this was a redis server running on the clog instance, but we later started using a managed redis server for other things so migrated this to. Our actual Clog instance is a 4GB DO instance. That’s it. Initially it was a 2GB (which was $10), so I don’t think we’re too far off the linked HN discussion.
The app to read the queue and add to Clickhouse is… simple. Brutally simple. Written in PHP using the PHP Redis extension in an afternoon, it runs BLPOP in an infinite loop to take an entry, run some very basic input processing (see next), and insert it into Clickhouse.
That processing is the key to how this system stays (fairly) speedy and is 100% not my idea. Uber is one of the first I could find who detailed how splitting up log keys from log values can make querying much more efficient. Combined with materialized views, we can get something very robust that will handle 90% of things we throw at it
Say we have a JSON log like so:
{
"created": "2022-12-25T13:37:00.12345Z",
"event_type": "http_response",
"http_route": "api.example"
}This is turned into a set of keys and values based on type:
"datetime_keys": ["created"],
"datetime_values": [DateTime(2022-12-25T13:37:00.12345Z)],
"string_keys": ["event_type", "http_route"],
"string_values": ["http_response", "api.example"]Our clickhouse logs table is:
- Partitioned by log created date;
- Has some top-level columns for things we’ll always have like application name, environment, etc;
- Array-based string columns for the *_keys columns;
- Array-based type-specific columns the *_values columns;
- A set of materialized views for pre-defined columns e.g.
matcol_event_type String MATERIALIZED string_values[indexOf(string_keys, 'event_type')]. This pulls out the value of event_type, and creates a virtual column that is stored. This makes queries for these columns much quicker. - A data retention policy to automatically remove data after 180 days.
This isn’t perfect. Not by a long shot. But it means we’ve been able to store our logs and just… not worry about costs spiralling out of control. A combination of a short retention time, Clickhouse’s in-built compression, and just realising that most people aren’t going to be generating TBs of logs a day, means we’ve flown by with this system.
Querying & Analysing
Querying is, again, very simple. Clickhouse offers packages for most languages, but also supports MySQL (and other) interfaces. We already have a back-office tool (in my experience, one of the first things you should work on), that makes it drop-dead simple to add a new screen and connect it to Clickhouse.
From there we can list logs with basic filters and facets. The big advantage I’ve found here over other log-specific tools is we can be a bit smart and link back into the application. For example, if a log includes a “auth_user_id” or “requested_entity_id”, we can link this to an existing information page in our back-office automatically.
Conclusions
There are definitely rough edges in Clog. A big one is that it’s simply an internal tool which means existing knowledge of other tools is lost. Some of the querying and filtering can definitely use some UX love. The alerts are hard-coded. And more.
But, in the two plus years we’ve been using Clog it has cost us a couple hundred dollars and all told, a day or two of my time, and in return saved us an order of magnitude more when pricing up hosted cloud options. This has given us a much longer runway.
I 100% wouldn’t recommend DIY NIH options for everything, but I Clog has paid off for what we needed.
February 12, 2023
On association by Graham Lee
My research touches on the professionalisation (or otherwise) of software engineering, and particularly the association (or not) of software engineers with a professional body, or with each other (or not) through a professional body. So what’s that about?
In Engagement Motivations in Professional Associations, Mark Hager uses a model that separates incentives to belong to a professional association into public incentives (i.e. those good for the profession as a whole, or for society as a whole) and private incentives (i.e. those good for an individual practitioner). Various people have tried to argue that people are only motivated by the private incentives (i.e. de Tocqueville’s “enlightened self-interest”).
Below, I give a quick survey of the incentives in this model, and informally how I see them enacted in computing. If there’s a summary, it’s that any idea of professionalism has been enclosed by the corporate actors.
Public incentives
Promoting greater appreciation of field among practitioners
My dude, software engineering has this in spades. Whether it’s a newsletter encouraging people to apply formal methods to their work, a strike force evangelising the latest programming language, or a consultant explaining that the reason their methodology is failing is that you don’t methodologise hard enough, it’s not incredibly clear that you can be in computering unless you’re telling everyone else what’s wrong with the way they computer. This is rarely done through formal associations though: while the SWEBOK does exist, I’d wager that the fraction of software engineers who refer to it in their work is 0 whatever floating point representation you’re using.
Ironically, the software craftsmanship movement suggests that a better way to promote good practice than professional associations is through medieval-style craft guilds, when professional associations are craft guilds that survived into the 20th century, with all the gatekeeping and back-scratching that entails.
Promoting public awareness of contributions in the field
If this happens, it seems to mostly be left to the marketing departments of large companies. The last I saw about augmented reality in the mainstream media was an advert for a product.
Influencing legislation and regulations that affect the field
Again, you’ll find a lot of this done in the policy departments of large companies. The large professional societies also get involved in lobbying work, but either explicitly walk back from discussions of regulation (ACM) or limit themselves to questions of research funding. Smaller organisations lobby on single-issue platforms (e.g. FSF Europe and the “public money, public code” campaign; the Documentation Foundation’s advocacy for open standards).
Maintaining a code of ethics for practice
It’s not like computering is devoid of ethics issues: artificial intelligence and the world of work; responsibility for loss of life, injury, or property damage caused by defective software; intellectual property and ownership; personal liberty, privacy, and data sovereignty; the list goes on. The professional societies, particularly those derived from or modelled on the engineering associations (ACM, IEEE, BCS), do have codes of ethics. Other smaller groups and individuals try to propose particular ethical codes, but there’s a network effect in play here. A code of ethics needs to be popular enough that clients of computerists and the public know about it and know to look out for it, with the far extreme being 100% coverage: either you have committed to the Hippocratic Oath, or you are not a practitioner of medicine.
Private incentives
Access to career information and employment opportunities
If you’re early-career, you want a job board to find someone who’s hiring early career roles. If you’re mid or senior career, you want a network where you can find out about opportunities and whether they’re worth pursuing. I don’t know if you’ve read the news lately, but staying employed in computering isn’t going great at the moment.
Opportunities to gain leadership experiences
How do you get that mid-career role? By showing that you can lead a project, team, or have some other influence. What early-career role gives you those opportunities? crickets Ad hoc networking based on open source seems to fill in for professional association here: rather than doing voluntary work contributing to Communications of the ACM, people are depositing npm modules onto the web.
Access to current information in the field
Rather than reading Communications of the ACM, we’re all looking for task-oriented information at the time we have a task to complete: the Q&A websites, technology-specific podcasts and video channels are filling in for any clearing house of professional advancement (to the point where even for-profit examples like publishing companies aren’t filling the gaps: what was the last attempt at an equivalent to Code Complete, 2nd Edition you can name?). This leads to a sort of balkanisation where anyone can quickly get up to speed on the technology they’re using, and generalising from that or building a holistic view is incredibly difficult. Certain blogs try to fill that gap, but again are individually published and not typically associated with any professional body.
Professional development or education programs
We have degree programs, and indeed those usually have accredited curricula (the ACM has traditionally been very active in that field, and the BCS in the UK). But many of the degrees are Computer Science rather than Software Engineering, and do they teach QA, or systems administration, or project management, or human-computer interaction? Are there vocational courses in those topics? Are they well-regarded: by potential students, by potential employers, by the public?
And then there are vendor certifications.
February 03, 2023
Reading List 300 by Bruce Lawson (@brucel)
Wow, 300 Reading Lists!
- Link o’ The Month: The Web Platform Is Back – Adobe writes “many of us now think that requiring Web frameworks on top of the standards was a transition phase, which is coming to its end as the Web Platform reaches a new level of maturity … Staying close to the Web Platform, without adding more than strictly needed on top of it, will help us create efficient and durable Web sites and applications. That’s the approach we are taking for upcoming tools”
- Related: Speed for who? – Andy Bell, a Northerner, gets righteously grumpy
- Three attributes for better web forms by Jeremy Keith. Try it out with this mobile form simulator
- (Almost) everything about storing data on the web (actually, storing data in the browser)
- The truth about CSS selector performance
- Blind news audiences are being left behind in the data visualisation revolution: here’s how we fix that
- There’s an AI for that – “AI use cases. Updated daily”
- Vivaldi Social on Mastodon: A Step-by-Step Tutorial – I’m using Viviadi’s mastodon instance, as I trust my old Opera chums to keep it stable and keep my data safe. Ruari’s tutorial is largely applicable to all instances, however.
- App stores, antitrust and their links to net neutrality: A review of the European policy and academic debate leading to the EU Digital Markets Act
- The IAB loves tracking users. But it hates users tracking them. – shady shenanigans from the Interactive Advertising Bureau. By Tezza.
February 02, 2023
The NTIA report on mobile app ecosystems by Bruce Lawson (@brucel)
The National Telecommunications and Information Administration (part of US Dept of Commerce) Mobile App Competition Report came out yesterday (1 Feb). Along with fellow Open Web Advocacy chums, I briefed them and also personally commented.
Key Policy Issue #1
Consumers largely can’t get apps outside of the app store model, controlled by Apple and Google. This means innovators have very limited avenues for reaching consumers.
Key Policy Issue #2
Apple and Google create hurdles for developers to compete for consumers by imposing technical limits, such as restricting how apps can function or requiring developers to go through slow and opaque review processes.
The report
I’m very glad that, like other regulators, we’ve helped them understand that there’s not a binary choice between single-platform iOS and Android “native” apps, but Web Apps (AKA “PWA”, Progressive Web Apps) offer a cheaper to produce alternative, as they use universal, mature web technologies:
Web apps can be optimized for design, with artfully crafted animations and widgets; they can also be optimized for unique connectivity constraints, offering users either a download-as-you go experience for low-bandwidth environments, or an offline mode if needed.
However, the mobile duopoly restrict the installation of web apps, favouring their own default browsers:
commenters contend that the major mobile operating system platforms—both of which derive revenue from native app downloads through their mobile app stores & whose own browsers derive significant advertising revenue—have acted to stifle implementation & distribution of web apps
NTIA recognises that this is a deliberate choice by Apple and (to a lesser extent) by Google:
developers face significant hurdles to get a chance to compete for users in the ecosystem, and these hurdles are due to corporate choices rather than technical necessities
NTIA explicitly calls out the Apple Browser Ban:
any web browser downloaded from Apple’s mobile app store runs on WebKit. This means that the browsers that users recognize elsewhere—on Android and on desktop computers—do not have the same functionality that they do on those other platforms.
It notes that WebKit has implemented fewer features that allow Web Apps to have similar capabilities as its iOS single-platform Apps, and lists some of the most important with the dates they were available in Gecko and Blink, continuing
According to commenters, lack of support for these features would be a more acceptable condition if Apple allowed other, more robust, and full-featured browser engines on its operating system. Then, iOS users would be free to choose between Safari’s less feature-rich experience (which might have other benefits, such as privacy and security features), and the broader capabilities of competing browsers (which might have other borrowers costs, such as greater drain on system resources and need to adjust more settings). Instead, iOS users are never given the opportunity to choose meaningfully differentiated browsers and experience features that are common for Android users—some of which have been available for over a decade.
Regardless of Apple’s claims that the Apple Browser Ban is to protect their users,
Multiple commenters note that the only obvious beneficiary of Apple’s WebKit restrictions is Apple itself, which derives significant revenue from its mobile app store commissions
The report concludes that
Congress should enact laws and relevant agencies should consider measures [aimed at] Getting platforms to allow installation and full functionality of third-party web browsers. To allow web browsers to be competitive, as discussed above, the platforms would need to allow installation and full functionality of the third-party web browsers. This would require platforms to permit third-party browsers a comparable level of integration with device and operating system functionality. As with other measures, it would be important to construct this to allow platform providers to implement reasonable restrictions in order to protect user privacy, security, and safety.
The NTIA joins the Australian, EU, and UK regulators in suggesting that the Apple Browser Ban stifles competition and must be curtailed.
The question now is whether Apple will do the right thing, or seek to hurl lawyers with procedural arguments at it instead, as they’re doing in the UK now. It’s rumoured that Apple might be contemplating about thinking about speculating about considering opening up iOS to alternate browsers for when the EU Digital Markets Act comes into force in 2024. But for every month they delay, they earn a fortune; it’s estimated that Google pays Apple $20 Billion to be the default search engine in Safari, and the App Store earned Apple $72.3 Billion in 2020 – sums which easily pay for snazzy lawyers, iPads for influencers, salaries for Safari shills, and Kool Aid for WebKit wafflers.
Place your bets!
January 30, 2023
In 1701, Asano Naganori, a feudal lord in Japan, was summoned to the shogun’s court in Edo, the town now called Tokyo. He was a provincial chieftain, and knew little about court etiquette, and the etiquette master of the court, Kira Kozuke-no-Suke, took offence. It’s not exactly clear why; it’s suggested that Asano didn’t bribe Kira sufficiently or at all, or that Kira felt that Asano should have shown more deference. Whatever the reasoning, Kira ridiculed Asano in the shogun’s presence, and Asano defended his honour by attacking Kira with a dagger.
Baring steel in the shogun’s castle was a grievous offence, and the shogun commanded Asano to atone through suicide. Asano obeyed, faithful to his overlord. The shogun further commanded that Asano’s retainers, over 300 samurai, were to be dispossessed and made leaderless, and forbade those retainers from taking revenge on Kira so as to prevent an escalating cycle of bloodshed. The leader of those samurai offered to divide Asano’s wealth between all of them, but this was a test. Those who took him up on the offer were paid and told to leave. Forty-seven refused this offer, knowing it to be honourless, and those remaining 47 reported to the shogun that they disavowed any loyalty to their dead lord. The shogun made them rōnin, masterless samurai, and required that they disperse. Before they did, they swore a secret oath among themselves that one day they would return and avenge their master. Then each went their separate ways. These 47 rōnin immersed themselves into the population, seemingly forgoing any desire for revenge, and acting without honour to indicate that they no longer followed their code. The shogun sent spies to monitor the actions of the rōnin, to ensure that their unworthy behaviour was not a trick, but their dishonour continued for a month, two, three. For a year and a half each acted dissolutely, appallingly; drunkards and criminals all, as their swords went to rust and their reputations the same.
A year and a half later, the forty-seven rōnin gathered together again. They subdued or killed and wounded Kira’s guards, they found a secret passage hidden behind a scroll, and in the hidden courtyard they found Kira and demanded that he die by suicide to satisfy their lord’s honour. When the etiquette master refused, the rōnin cut off Kira’s head and laid it on Asano’s grave. Then they came to the shogun, surrounded by a public in awe of their actions, and confessed. The shogun considered having them executed as criminals but instead required that they too die by suicide, and the rōnin obeyed. They were buried, all except one who was not present and who lived on, in front of the tomb of their master. The tombs are a place to be visited even today, and the story of the 47 rōnin is a famous one both inside and outside Japan.
You might think: why have I been told this story? Well, there were 47 of them. 47 is a good number. It’s the atomic number of silver, which is interesting stuff; the most electrically conductive metal. (During World War II, the Manhattan Project couldn’t get enough copper for the miles of wiring they needed because it was going elsewhere for the war effort, so they took all the silver out of Fort Knox and melted it down to make wire instead.) It’s strictly non-palindromic, which means that it’s not only not a palindrome, it remains not a palindrome in any base smaller than itself. And it’s how old I am today.
Yes! It’s my birthday! Hooray!

I have had a good birthday this year. The family and I had delightful Greek dinner at Mythos in the Arcadian, and then yesterday a bunch of us went to the pub and had an absolute whale of an afternoon and evening, during which I became heartily intoxicated and wore a bag on my head like Lord Farrow, among other things. And I got a picture of the Solvay Conference from Bruce.

This year is shaping up well; I have some interesting projects coming up, including one will-be-public thing that I’ve been working on and which I’ll be revealing more about in due course, a much-delayed family thing is very near its end (finally!), and in general it’s just gotta be better than the ongoing car crash that the last few years have been. Fingers crossed; ask me again in twelve months, anyway. I’ve been writing these little posts for 21 years now (last year has more links) and there have been ups and downs, but this year I feel quite hopeful about the future for the first time in a while. This is good news. Happy birthday, me.

January 27, 2023
Trying the PICO-8 by James Nutt (@zerosumjames)
I got myself a little present for Christmas. The PICO-8. The PICO-8 is a fantasy console, which is an emulator for a console that doesn’t exist. The PICO-8 comes with its own development and runtime environment, packaged into a single slick application with a beautiful aesthetic.
![]()
It also comes with a pretty strict set of constraints in which to work your magic.
Display: 128x128 16 colours
Cartridge size: 32k
Sound: 4 channel chip blerps (I assume this is an industry term)
Code: P8 Lua
CPU: 4M vm insts/sec
Sprites: 256 8x8 sprites
Map: 128x32 tiles
The constraints are appealing. Modern development at big companies sometimes seems like being at an all-you-can-eat buffet with the company credit card. Run out of CPU? Your boss can fix that with whatever the best new MacBook is. Webserver process eating RAM like candy? Doesn’t matter, that’s what automatic load balancers and infinite horizontal scaling is for.
With the PICO-8, there appears to be no such negotiation. There’s something liberating about this. By putting firm limits on the scope of what you can create, you know when to stop. If you hit the limit, you know you have to either admit that the project is as done as it’s going to get, or you need to refine or remove something that’s already there. Infinite potential is both a luxury and a curse.
What you get is what you get, and what you get is enough for a wide community of enthusiasts to create some beautiful and entertaining games that you can play directly in the browser, in your own copy of PICO-8, or on one of several fan-made hardware solutions.

My favourite feature is actually secondary to the main function of the console. Cartridges can be exported as PNG files, with game data steganographically hidden within. Each one of the below files is a playable cartridge that can be loaded into the PICO-8 console.

There’s something tactile that didn’t fully transfer from cartridge to CD and definitely didn’t transfer from CD to digital download. You can’t quite argue that a folder of PNGs isn’t a digital download, but somewhere in the dusty corners of my memory, I recall the sound of plastic rattling against plastic and a long day of zero responsibility ahead.
January 23, 2023
Apple: we’re so great for consumers we want to block investigation that could vindicate us by Bruce Lawson (@brucel)
Regular readers to this chucklefest will recall that I’ve been involved with briefing competition regulators in UK, US, Australia, Japan and EU about the Apple Browser Ban – Apple’s anti-competitive requirement that anything that can browse the web on iOS/iPad must use its WebKit engine. This allows Apple to stop web apps becoming as feature-rich as its iOS apps, for which it can charge a massive fee for listing in its monopoly App Store.
The UK’s Competition and Markets Authority recently announced a market investigation reference (MIR) into the markets for mobile browsers (particularly browser engines). The CMA may decide to make a MIR when it has reasonable grounds for suspecting that a feature or combination of features of a market or markets in the UK prevents, restricts, or distorts competition (PDF).
You would imagine that Apple would welcome this opportunity to be scrutinised, given that Apple told CMA (PDF) that
By integrating WebKit into iOS, Apple is able to guarantee robust user privacy protections for every browsing experience on iOS device… . WebKit has also been carefully designed and optimized for use on iOS devices. This allows iOS devices to outperform competitors on web-based browsing benchmarks… Mandating Apple to allow apps to use third-party rendering engines on iOS, as proposed by the IR, would break the integrated security model of iOS devices, reduce their privacy and performance, and ultimately harm competition between iOS and Android devices.
Yet despite Apple’s assertion that it is simply the best, better than all the rest, it is weirdly reluctant to see the CMA investigate it. You would assume that Apple are confident that it would be vindicated by CMA as better than anyone, anyone they’ve ever met. Yet Apple applied to the Competition Appeal Tribunal (PDF, of course), seeking
1. An Order that the MIR Decision is quashed.
2. A declaration that the MIR Decision and market investigation purportedly launched by
reference to it are invalid and of no legal effect.
In its Notice of Application, Apple also seeks interim relief in the form of a stay of the market investigation pending determination of the application.
Why would this be? I don’t know (I seem no longer to be on not-Steve’s Xmas card list). But it’s interesting to note that a CMA Market Investigation can have real teeth. It has previously forced forced the sale of airports and hospitals (gosh! A PDF) in other sectors.
A market investigation lowers the hurdle for the CMA: it doesn’t have to prove wrongdoing, just adverse effects on competition (abbreviated as AEC, which in other antitrust jurisdictions, however, stands for “as efficient competitor”) and has greater powers to impose remedies. Otherwise a conventional antitrust investigation of Apple’s conduct would be required, and Apple would have to be shown to have abused a dominant position in the relevant market. Apple would like to deprive the CMA of its more powerful tool, and essentially argues that the CMA has deprived itself of that tool by failing to abide by the applicable statute.
It’s rumoured that Apple might be contemplating about thinking about speculating about considering opening up iOS to alternate browsers for when the EU Digital Markets Act comes into force in 2024. But for every month they delay, they earn a fortune; it’s estimated that Google pays Apple $20 Billion to be the default search engine in Safari, and the App Store earned Apple $72.3 Billion in 2020 – sums which easily pay for snazzy lawyers, iPads for influencers, salaries for Safari shills, and Kool Aid for WebKit wafflers.
(Last Updated on )
January 16, 2023
Low-stakes conspiracy theory: they were invented by word processing marketers to justify spell-check features that weren’t necessary.
Evidence: the Oxford English Dictionary (Oxford being in Britain) entry for “-ise” suffix’s first sense is “A frequent spelling of -ize suffix, suffix forming verbs, which see.” So in a British dictionary, -ize is preferred. But in a computer, I have to change my whole hecking country to be able to write that!
January 13, 2023
Reading List 299 by Bruce Lawson (@brucel)
Due to annoyances in the economy (thanks, Putin, and Liz Truss) I find myself once again on the jobs market. Read my LinkTin C.V. thingie, then hire me to make your digital products more accessible, faster and full of standardsy goodness!
- A CSS challenge: skewed highlight by my old chum Vadim Makeev.
- What does it look like for the web to lose? by Chris Coyier
- Our top Core Web Vitals recommendations for 2023 “A collection of the best practices that the Chrome DevRel team believes are the most effective ways to improve Core Web Vitals performance in 2023.”
- Counting unique visitors without using cookies, UIDs or fingerprinting – “Building a web analytics service without cookies poses a tricky problem: How do you distinguish unique visitors?”
- Top 5 Accessibility Issues in 2022 – the old ones are the worst
- Component library accessibility audit – some interesting points about the difficulty of auditing individual components that are out of context
- A Future Where XR is Born Accessible – “This case study provides an in-depth look at the steps taken to launch and sustain the Initiative in its first year of operation and outlines how XR Access is evolving and laying the groundwork for its next stage of maturity.”
- How Indie Studios Are Pioneering Accessible Game Design – Smaller shops prove that you don’t need a AAA budget to create games for everyone.
- Setup iPhone or iPad for iOS mobile Accessibility testing – a 12 minute video
- Things CSS Could Still Use Heading Into 2023 by Chris Coyier
- Web apps could de-monopolize mobile devices writes Cory Doctorow
- Welcome to this course on Prompt Engineering! – “I like to think of Prompt Engineering (PE) as “How to talk to AI to get it to do what you want”.”
- Teachable Machine – “Train a computer to recognize your own images, sounds, & poses. A fast, easy way to create machine learning models for your sites, apps, and more – no expertise or coding required.”
- What Did We Get Stuck In Our Rectums Last Year? “All reports are taken from the U.S. Consumer Product Safety Commission’s database of emergency room visits” – also features all other orifices.
In March, I shall be keynoting at axe-con with a talk called Whose web is it, anyway?. It’s free.
January 02, 2023
What to do about hotlinking by Stuart Langridge (@sil)
Hotlinking, in the context I want to discuss here, is the act of using a resource on your website by linking to it on someone else’s website. This might be any resource: a script, an image, anything that is referenced by URL.
It’s a bit of an anti-social practice, to be honest. Essentially, you’re offloading the responsibility for the bandwidth of serving that resource to someone else, but it’s your site and your users who get the benefit of that. That’s not all that nice.
Now, if the “other person’s website” is a CDN — that is, a site deliberately set up in order to serve resources to someone else — then that’s different. There are many CDNs, and using resources served from them is not a bad thing. That’s not what I’m talking about. But if you’re including something direct from someone else’s not-a-CDN site, then… what, if anything, should the owner of that site do about it?
I’ve got a fairly popular, small, piece of JavaScript: sorttable.js, which makes an HTML table be sortable by clicking on the headers. It’s existed for a long time now (the very first version was written twenty years ago!) and I get an email about it once a week or so from people looking to customise how it works or ask questions about how to do a thing they want. It’s open source, and I encourage people to use it; it’s deliberately designed to be simple1, because the target audience is really people who aren’t hugely experienced with web development and who can add sortability to their HTML tables with a couple of lines of code.
The instructions for sorttable are pretty clear: download the library, then put it in your web space and include it. However, some sites skip that first step, and instead just link directly to the copy on my website with a <script> element. Having looked at my bandwidth usage recently, this happens quite a lot2, and on some quite high-profile sites. I’m not going to name and shame anyone3, but I’d quite like to encourage people to not do that, if there’s a way to do it. So I’ve been thinking about ways that I might discourage hotlinking the script directly, while doing so in a reasonable and humane fashion. I’m also interested in suggestions: hit me up on Mastodon at @sil@mastodon.social or Twitter4 as @sil.
Move the script to a different URL
This is the obvious thing to do: I move the script and update my page to link to the new location, so anyone coming to my page to get the script will be wholly unaffected and unaware I did it. I do not want to do this, for two big reasons: it’s kicking the can down the road, and it’s unfriendly.
It’s can-kicking because it doesn’t actually solve the problem: if I do nothing else to discourage the practice of hotlinking, then a few years from now I’ll have people hotlinking to the new location and I’ll have to do it again. OK, that’s not exactly a lot of work, but it’s still not a great answer.
But more importantly, it’s unfriendly. If I do that, I’ll be deliberately breaking everyone who’s hotlinking the script. You might think that they deserve it, but it’s not actually them who feel the effect; it’s their users. And their users didn’t do it. One of the big motives behind the web’s general underlying principle of “don’t break the web” is that it’s not reasonable to punish a site’s users for the bad actions of the site’s creators. This applies to browsers, to libraries, to websites, the whole lot. I would like to find a less harsh method than this.
Move the script to a different dynamic URL
That is: do the above, but link to a URL which changes automatically every month or every minute or something. The reason that I don’t want to do this (apart from the unfriendly one from above, which still applies even though this fixes the can-kicking) is that this requires server collusion; I’d need to make my main page be dynamic in some way, so that links to the script also update along with the script name change. This involves faffery with cron jobs, or turning the existing static HTML page into a server-generated page, both of which are annoying. I know how to do this, but it feels like an inelegant solution; this isn’t really a technical problem, it’s a social one, where developers are doing an anti-social thing. Attempting to solve social problems with technical measures is pretty much always a bad idea, and so it is in this case.
Contact the highest-profile site developers about it
I’m leaning in this direction. I’m OK with smaller sites hotlinking (well, I’m not really, but I’m prepared to handwave it; I made the script and made it easy to use exactly to help people, and if a small part of that general donation to the universe includes me providing bandwidth for it, then I can live with that). The issue here is that it’s not always easy to tell who those heavy-bandwidth-consuming sites are. It relies on the referrer being provided, which it isn’t always. It’s also a bit more work on my part, because I would want to send an email saying “hey, Site X developers, you’re hotlinking my script as you can see on page sitex.example.com/sometable.html and it would be nice if you didn’t do that”, but I have no good way of identifying those pages; the document referrer isn’t always that specific. If I send an email saying “you’re hotlinking my script somewhere, who knows where, please don’t do that” then the site developers are quite likely to put this request at the very bottom of their list, and I don’t blame them.
Move the script and maliciously break the old one
This is: I move the script somewhere else and update my links, and then I change the previous URL to be the same script but it does something like barf a complaint into the console log, or (in extreme cases based on suggestions I’ve had) pops up an alert box or does something equally obnoxious. Obviously, I don’t wanna do this.
Legal-ish things
That is: contact the highest profile users, but instead of being conciliatory, be threatening. “You’re hotlinking this, stop doing it, or pay the Hotlink Licence Fee which is one cent per user per day” or similar. I think the people who suggest this sort of thing (and the previous malicious approach) must have had another website do something terrible to them in a previous life or something and now are out for revenge. I liked John Wick as much as the next poorly-socialised revenge-fantasy tech nerd, but he’s not a good model for collaborative software development, y’know?
Put the page (or whole site) behind a CDN
I could put the site behind Cloudflare (or perhaps a better, less troubling CDN) and then not worry about it; it’s not my bandwidth then, it’s theirs, and they’re fine with it. This used to be the case, but recently I moved web hosts5 and stepped away from Cloudflare in so doing. While this would work… it feels like giving up, a bit. I’m not actually solving the problem, I’m just giving it to someone else who is OK with it.
Live with it
This isn’t overrunning my bandwidth allocation or anything. I’m not actually affected by this. My complaint isn’t important; it’s more a sort of distaste for the process. I’d like to make this better, rather than ignoring it, even if ignoring it doesn’t mean much, as long as I’m not put to more inconvenience by fixing it. We want things to be better, after all, not simply tolerable.
So… what do you think, gentle reader? What would you do about it? Answers on a postcard.
- and will stay simple; I’d rather sorttable were simple and relatively bulletproof than comprehensive and complicated. This also explains why it’s not written in very “modern” JS style; the best assurance I have that it works in old browsers that are hard to test in now is that it DID work in them and I haven’t changed it much ↩
- in the last two weeks I’ve had about 200,000 hits on sorttable.js from sites that hotlink it, which ain’t nothin’ ↩
- yet, at least, so don’t ask ↩
- if you must ↩
- to the excellent Mythic Beasts, who are way better than the previous hosts ↩
December 20, 2022
Bad performance is bad accessibility by Bruce Lawson (@brucel)
What is “accessibility”? For some, it’s about ensuring that your sites and apps don’t block people with disabilities from completing tasks. That’s the main part of it, but in my opinion it’s not all of the story. Accessibility, to me, means taking care to develop digital services that are inclusive as possible. That means inclusive of people with disabilities, of people outside Euro-centric cultures, and people who don’t have expensive, top-the-range hardware and always-on cheap fast networks.
In his closely argued post The Performance Inequality Gap, 2023, Alex Russell notes that “When digital is society’s default, slow is exclusionary”, and continues
sites continue to send more script than is reasonable for 80+% of the world’s users, widening the gap between the haves and the have-nots. This is an ethical crisis for the frontend.
Big Al goes on to suggest that in order to reach interactivity in less than 5 seconds on first load, we should send no more that ~150KiB of HTML, CSS, images, and render-blocking font resources, and no more than ~300-350KiB of JavaScript. (If you want to know the reasoning behind this, Alex meticulously cites his sources in the article; read it!)
Now, I’m not saying this is impossible using modern frameworks and tooling (React, Next.js etc) that optimise for good “developer experience”. But it is a damned sight harder, because such tooling prioritises developer experience over user experience.
In January, I’ll be back on the jobs market (here’s my LinkTin resumé!) so I’ve been looking at what’s available. Today I saw a job for a Front End lead who will “write the first lines of front end code and set the tone for how the team approaches user-facing software development”. The job spec requires a “bias towards solving problems in simple, elegant ways”, and the candidate should be “confident building with…reliability and accessibility in mind”. Yet, weirdly, even though the first lines of code are yet to be written, it seems the tech stack is already decided upon: React and Next.js.
As Alex’s post shows, such tooling conspires against simplicity and elegance, and certainly against reliability and accessibility. To repeat his message:
When digital is society’s default, slow is exclusionary
Bad performance is bad accessibility.
December 19, 2022
Reading List 298 by Bruce Lawson (@brucel)
- The UK competition regulator just published its statement of issues (PDF, 17 pp) for its new Mobile browsers and cloud gaming market investigation.
- Apple is reportedly preparing to allow third-party app stores on the iPhone – let’s see; this is “reportedly”, and nothing about PWA-capable 3rd party browser engines on iThings. But it’s the sweet smell of #appleBrowserBan change blowing in the wind.
- The Web’s Next Transition – Kent C. Dodds thinks it is “Progressively Enhanced Single Page Apps”. Progressive Enhancement? Yay. Single Page Apps? Meh. Talking of which…
- Shared Element Transitions is now View Transitions and when smooth and simple transitions with the View Transitions API are shipping for multi-page apps, we’ll be able to get the snappy feel of single page apps, without all the crap and accessibility problems. Yay!
- Access & Use shows what it needs to make dynamic elements in websites accessible and usable for all.
- Introducing Codux – a new visual IDE for easing and accelerating the development of React projects from Wix. (I worked on this team).
- Shadow DOM and accessibility: the trouble with ARIA and how the Accessibility Object Model solves the problem
- You Don’t Need ARIA For That – “ARIA usage certainly has its place. But overall, reduced usage of ARIA will, ironically, greatly increase accessibility.”
- Making microservices accessible
- Tab order in CSS Masonry – Chromium discussion on what the order should be
- Meta is being sued for $2 billion for exacerbating Ethiopia’s civil war -Facebook’s algorithm helped fuel the viral spread of hate and violence during Ethiopia’s civil war, a legal case alleges.”
- How I set up a Twitter archive with Tweetback – flame-haired FOSS adonis Stuart Langridge has step-by-step instructions. Needs you to be able to do stuff in Terminal.
- Make your own simple, public, searchable Twitter archive – download your archive from twitter, this tool processes the zip file (on your local machine), upload the resulting html pages to your archive URL. Simpler than using Tweetback, but less customisable.
- And finally: Musk-era Twitter emulator
(Last Updated on )
How I set up a Twitter archive with Tweetback by Stuart Langridge (@sil)
Twitter currently has problems. Well, one specific problem, which is the bloke who bought it. My solution to this problem has been to move to Mastodon (@sil@mastodon.social if you want to do the same), but I’ve invested fifteen years of my life providing twitter.com with free content so I don’t really want it to go away. Since there’s a chance that the whole site might vanish, or that it continues on its current journey until I don’t even want my name associated with it any more, it makes sense to have a backup. And obviously, I don’t want all that lovely writing to disappear from the web (how would you all cope without me complaining about some random pub’s music in 2011?!), so I wanted to have that backup published somewhere I control… by which I mean my own website.
So, it would be nice to be able to download a list of all my tweets, and then turn that into some sort of website so it’s all still available and published by me.
Fortunately, Zach Leatherman came to save us by building a tool, Tweetback, which does a lot of the heavy lifting on this. Nice one, that man. Here I’ll describe how I used Tweetback to set up my own personal Twitter archive. This is unavoidably a bit of a developer-ish process, involving the Terminal and so on; if you’re not at least a little comfortable with doing that, this might not be for you.
Step 1: get a backup from Twitter
This part is mandatory. Twitter graciously permit you to download a big list of all the tweets you’ve given them over the years, and you’ll need it for this. As they describe in their help page, go to your Twitter account settings and choose Your account > Download an archive of your data. You’ll have to confirm your identity and then say Request data. They then go away and start constructing an archive of all your Twitter stuff. This can take a couple of days; they send you an email when it’s done, and you can follow the link in that email to download a zip file. This is your Twitter backup; it contains all your tweets (and some other stuff). Stash it somewhere; you’ll need a file from it shortly.
Step 2: get the Tweetback code
You’ll need both node.js and git installed to do this. If you don’t have node.js, go to nodejs.org and follow their instructions for how to download and install it for your computer. (This process can be fiddly; sorry about that. I suspect that most people reading this will already have node installed, but if you don’t, hopefully you can manage it.) You’ll also need git installed: Github have some instructions on how to install git or Github Desktop, which should explain how to do this stuff if you don’t already have it set up.
Now, you need to clone the Tweetback repository from Github. On the command line, this looks like git clone https://github.com/tweetback/tweetback.git; if you’re using Github Desktop, follow their instructions to clone a repository. This should give you the Tweetback code, in a folder on your computer. Make a note of where that folder is.
Step 3: install the Tweetback code
Open a Terminal on your machine and cd into the Tweetback folder, wherever you put it. Now, run npm install to install all of Tweetback’s dependencies. Since you have node.js installed from above, this ought to just work. If it doesn’t… you get to debug a bit. Sorry about that. This should end up looking something like this:
$ npm install
npm WARN deprecated @npmcli/move-file@1.1.2: This functionality has been moved to @npmcli/fs
added 347 packages, and audited 348 packages in 30s
52 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
Step 4: configure Tweetback with your tweet archive
From here, you’re following Tweetback’s own README instructions: they’re online at https://github.com/tweetback/tweetback#usage and also are in the README file in your current directory.
Open up the zip file you downloaded from Twitter, and get the data/tweets.js file from it. Put that in the database folder in your Tweetback folder, then edit that file to change window.YTD.tweet.part0 on the first line to module.exports, as the README says. This means that your database/tweets.js file will now have the first couple of lines look like this:
module.exports = [
{
"tweet" : {
Now, run npm run import. This will go through your tweets.js file and load it all into a database, so it can be more easily read later on. You only need to do this step once. This will print a bunch of lines that look like { existingRecordsFound: 0, missingTweets: 122 }, and then a bunch of lines that look like Finished count { count: 116 }, and then it’ll finish. This should be relatively quick, but if you’ve got a lot of tweets (I have 68,000!) then it might take a little while. Get yourself a cup of tea and a couple of biscuits and it’ll be done when you’ve poured it.
Step 5: Configure a subdirectory (optional)
If you’re setting up your own (sub)domain for your twitter archive, so it’ll be at the root of the website (so, https://twitter.example.com or whatever) then you can skip this step. However, if you’re going to put your archive in its own directory, so it’s not at the root (which I did, for example, at kryogenix.org/twitter), then you need to tell your setup about that.
To do this, edit the file eleventy.config.js, and at the end, before the closing }, add a new line, so the end of the file looks like this:
eleventyConfig.addPlugin(EleventyHtmlBasePlugin);
return {pathPrefix: "/twitter/"}
};
The string "/twitter/" should be whatever you want the path to the root of your Twitter archive to be, so if you’re going to put it at mywebsite.example.com/my-twitter-archive, set pathPrefix to be "/my-twitter-archive". This is only a path, not a full URL; you do not need to fill in the domain where you’ll be hosting this here.
Step 6: add metadata
As the Tweetback README describes, edit the file _data/metadata.js. You’ll want to change three values in here: username, homeLabel, and homeURL.
username is your Twitter username. Mine is sil: yours isn’t. Don’t include the @ at the beginning.
homeLabel is the thing that appears in the top corner of your Twitter archive once generated; it will be a link to your own homepage. (Note: not the homepage of this Twitter archive! This will be the text of a link which takes you out of the Twitter archive and to your own home.)
homeURL is the full URL to your homepage. (This is “https://kryogenix.org/” for me, for example. It is the URL that homeLabel links to.)

Step 7: (drum roll, please!) Build the site
OK. Now you’ve done all the setup. This step actually takes all of that and builds a website from all your tweets.
Run npm run build.
If you’ve got a lot of tweets, this can take a long time. It took me a couple of hours, I think, the first time I ran it. Subsequent runs take a lot less time (a couple of minutes for me, maybe even shorter for you if you’re less mouthy on Twitter), but the first run takes ages because it has to fetch all the images for all the tweets you’ve ever written. You’ll want a second cup of tea here, and perhaps dinner.
It should look something like this:
$ npm run build
> tweetback@1.0.0 build
> npx @11ty/eleventy --quiet
[11ty] Copied 1868 files / Wrote 68158 files in 248.58 seconds (3.6ms each, v2.0.0-canary.18)
You may get errors in here about being unable to fetch URLs (Image request error Bad response for https://pbs.twimg.com/media/C1VJJUVXEAE3VGE.jpg (404): Not Found and the like); this is because some Tweets link to images that aren’t there any more. There’s not a lot you can do about this, but it doesn’t stop the rest of the site building.
Once this is all done, you should have a directory called _site, which is a website containing your Twitter archive! Hooray! Now you publish that directory, however you choose: copy it up to your website, push it to github pages or Netlify or whatever. You only need the contents of the _site directory; that’s your whole Twitter archive website, completely self-contained; all the other stuff is only used for generating the archive website, not for running it once it’s generated.
Step 8: updating the site with newer tweets (optional)
If you’re still using Twitter, you may post more Tweets after your downloadable archive was generated. If so, it’d be nice to update the archive with the contents of those tweets without having to request a full archive from Twitter and wait two days. Fortunately, this is possible. Unfortunately, you gotta do some hoop-jumping to get it.
You see, to do this, you need access to the Twitter API. In the old days, people built websites with an API because they wanted to encourage others to interact with that website programmatically as well as in a browser: you built an ecosystem, right? But Twitter are not like that; they don’t really want you to interact with their stuff unless they like what you’re doing. So you have to apply for permission to be a Twitter developer in order to use the API.
To do this, as the Tweetback readme says, you will need a Twitter bearer token. To get one of those, you need to be a Twitter developer, and to be that, you have to fill in a bunch of forms and ask for permission and be manually reviewed. Twitter’s documentation explains about bearer tokens, and explains that you need to sign up for a Twitter developer account to get them. Go ahead and do that. This is an annoying process where they ask a bunch of questions about what you plan to do with the Twitter API, and then you wait until someone manually reviews your answers and decides whether to grant you access or not, and possibly makes you clarify your answers to questions. I have no good suggestions here; go through the process and wait. Sorry.
Once you are a Twitter developer, create an app, and then get its bearer token. You only get this once, so be sure to make a note of it. In a clear allusion to the delight that this whole process brings to users, it probably will begin by screaming AAAAAAAAAAAAAAA and then look like a bunch of incomprehensible gibberish.
Now to pull in new data, run:
TWITTER_BEARER_TOKEN=AAAAAAAAAAAAAAAAAAq3874nh93q npm run fetch-new-data
(substituting in the value of your token, of course, which will be longer.)
This will fetch any tweets that aren’t in the database because you made them since! And then run npm run build again to rebuild the _site directory, and re-publish it all.
I personally run these steps (fetch-new-data, then build, then publish) daily in a cron job, which runs a script with contents (approximately):
#!/bin/bash
cd "$(dirname "$0")"
echo Begin publish at $(date)
echo Updating Twitter archive
echo ========================
TWITTER_BEARER_TOKEN=AAAAAAAAAAAAAA9mh8j9808jhey9w34cvj3g3 npm run fetch-new-data 2>&1
echo Updating site from archive
echo ==========================
npm run build 2>&1
echo Publishing site
echo ===============
rsync -e "ssh" -az _site/ kryogenix.org:public_html/twitter 2>&1
echo Finish publish at $(date)
but how you publish and rebuild, and how often you do that, is of course up to you.
Step 9: improve the archive (optional, but good)
What Tweetback actually does is use your twitter backup to build an 11ty static website. (This is not all that surprising, since 11ty is also Zach’s static site builder.) This means that if you’re into 11ty you could make the archive better and more comprehensive by adding stuff. There are already some neat graphs of most popular tweets, most recent tweets, the emoji you use a lot (sigh) and so on; if you find things that you wish that your Twitter archive contained, file an issue with Tweetback, or better still write the change and submit it back so everyone gets it!
Step 10: add yourself to the list of people using the archive (optional, but you know you wanna)
Go to tweetback/tweetback-canonical and add yourself to the mapping.js file. What’s neat about this is that that file is used by tweetback itself. This means that if someone else with a Tweetback archive has a tweet which links to one of your Tweets, now their archive will link to your archive directly instead! It’s not just a bunch of separate sites, it’s a bunch of sites all of which are connected! Lots of connections between sites without any central authority! We could call this a collection of connections. Or a pile of connections. Or… a web!
That’s a good idea. Someone should do something with that concept.
Step 11: big hugs for Zach
You may, or may not, want to get off Twitter. Maybe you’re looking to get as far away as possible; maybe you just don’t want to lose the years of investment you’ve put in. But it’s never a bad thing to have your data under your control when you can. Tweetback helps make that happen. Cheers to Zach and the other contributors for creating it, so the rest of us didn’t have to. Tell them thank you.
December 06, 2022
Transferring to a new phone network, 2022 edition by Stuart Langridge (@sil)
Some posts are written so there’s an audience. Some are written to be informative, or amusing. And some are literally just documentation for me which nobody else will care about. This is one of those.
I’ve moved phone network. I’ve been with Three for years, but they came up with an extremely annoying new tactic, and so they must be punished. You see, I had an account with 4GB of data usage per month for about £15pm, and occasionally I’d go over that; a couple of times a year at most. That’s OK: I don’t mind buying some sort of “data booster” thing to give me an extra gig for the last few days before the next bill; seems reasonable.
But Three changed things. Now, you see, you can’t buy a booster to give yourself a bit of data until the end of the month. No, you have to buy a booster which gives you extra data every month, and then three days later when you’re in the new month, cancel it. There’s no way to just get the data for now.1
This is aggressively customer-hostile. There’s literally no reason to do this other than to screw people who forget to cancel it. Sure, have an option to buy a “permanent top-up”, no arguments with that. But there should also be an option to buy a temporary top-up, just once! There used to be!
I was vaguely annoyed with Three for general reasons anyway — they got rid of free EU roaming, they are unhelpful when you ask questions, etc — and so I was vaguely considering moving away regardless. But this was the straw that broke the camel’s back.2 So… time to look around.
I asked the Mastodon gang for suggestions, and I got lots, which is useful. Thank you for that, all.
The main three I got were Smarty, iD, and Giffgaff. Smarty are Three themselves in a posh frock, so that’s no good; the whole point of bailing is to leave Three. Giffgaff are great, and I’ve been hearing about their greatness for years, not least from popey, but they don’t do WiFi Calling, so they’re a no-no.3 And iD mobile looked pretty good. (All these new “MVNO” types of thing seem quite a lot cheaper than “traditional” phone operators. Don’t know why. Hooray, though.)
So off I went to iD, and signed up for a 30-day rolling SIM-only deal4. £7 per month. 12GB of data. I mean, crikey, that’s quite a lot better than before.
I need to keep my phone number, though, so I had to transfer it between networks. To do this, you need a “PAC” code from your old network, and you supply it to the new one. All my experience of dealing with phone operators is from the Old Days, and back then you had to grovel to get a PAC and your current phone network would do their best to talk you out of it. Fortunately, the iron hand of government regulation has put a stop to these sorts of shenanigans now (the UK has a good tech regulator, the Competition and Markets Authority5) and you can get a PAC, no questions asked, by sending an SMS with content “PAC” to 65075. Hooray. So, iD mobile sent me a new SIM in the post, and I got the PAC from Three, and then I told iD about the PAC (on the website: no person required), and they said (on the website), ok, we’ll do the switch in a couple of working days.
However, the SIM has some temporary number on it. Today, my Three account stopped working (indicating that Three had received and handled their end of the deal by turning off my account), and so I dutifully popped out the Three SIM from my phone6 and put in the new one.
But! Alas! My phone thought that it had the temporary number!
I think this is because Three process their (departing) end, there’s an interregnum, and then iD process their (arriving) end, and I was in the interregnum. I do not know what would have happened if someone rang my actual phone number during this period. Hopefully nobody did. I waited a few hours — the data connection worked fine on my phone, but it had the wrong number — and then I turned the phone off and left it off for ten minutes or so. Then… I turned it back on, and… pow! My proper number is mine again! Hooray!
That ought to have been the end of it. However, I have an Apple phone. So, in Settings > Phone > My Number, it was still reading the temporary number. Similarly, in Settings > Messages > iMessage > Send and Receive, it was also still reading the temporary number.
How inconvenient.
Some combination of the following fixed that. I’m not sure exactly what is required to fix it: I did all this, some more than once, in some random order, and now it seems OK: powering the phone off and on again; disabling iMessage and re-enabling it; disabling iMessage, waiting a few minutes, and then re-enabling it; disabling iMessage, powering off the phone, powering it back on again, and re-enabling it; editing the phone number in My Number (which didn’t seem to have any actual effect); doing a full network reset (Settings > General > Transfer or Reset Device > Reset > Reset Network Settings). Hopefully that’ll help you too.
Finally, there was voicemail. Some years ago, I set up an account with Sipgate, where I get a phone number and voicemail. The thing I like about this is that when I get voicemail on that number, it emails me an mp3 of the voicemail. This is wholly brilliant, and phone companies don’t do it; I’m not interested in ringing some number and then pressing buttons to navigate the horrible menu, and “visual voicemail” never took off and never became an open standard thing anyway. So my sipgate thing is brilliant. But… how do I tell my phone to forward calls to my sipgate number if I don’t answer? I did this once, about 10 years ago, and I couldn’t remember how. A judicious bit of web searching later, and I have the answer.
One uses a few Secret Network Codes to do this. It’s called “call diversion” or “call forwarding”, and you do it by typing a magic number into your phone dialler, as though you were ringing it as a number. So, let’s say your sipgate number is 0121 496 0000. Open up the phone dialler, and dial *61*01214960000# and press dial. That magic code, *61, sets your number to divert if you don’t answer it. Do it again with *62 to also divert calls when your phone is switched off. You can also do it again with *67 to divert calls when your phone is engaged, but I don’t do that; I want those to come through where the phone can let me switch calls.
And that’s how I moved phone networks. Stuart, ten years from now when you read this again, now you know how to do it. You’re welcome.
- Well, there is: you can spend twenty actual pounds to get unlimited data until the end of the month. But that’s loads of money. ↩
- is there an actual camel whose back was broken in some fable somewhere? this is a terribly unfortunate metaphor! ↩
- Coverage in my flat — for any network — is rubbish. So wifi calling is a hard requirement. I don’t know why this is — I’m in the city! Maybe the walls all have copper wiring in them like the room that Elodin was imprisoned in, I don’t know ↩
- I always buy my own phones, so I only ever need a SIM, and I don’t like being locked in ↩
- we, meaning Open Web Advocacy, have worked extensively with the CMA (and other regulators around the world) about assisting and requiring mobile phone manufacturers to provide browser diversity — that is, to make it so you can use web apps on your phone that are as capable as platform-specific apps, and the CMA are great ↩
- removing a SIM tray is harder than it looks when you don’t wear earrings. I had to search everywhere to find one of those little SIM tools ↩
December 03, 2022
Progress reversing iOS browser ban in UK, EU and Australia by Bruce Lawson (@brucel)
I wrote a couple of short blog posts for Open Web Advocacy (of which I’m a founder member) on our progress in getting regulators to overturn the iOS browser ban and end Apple’s stranglehold over the use of Progressive Web Apps on iThings.
TL:DR; we’re winning.
Happy Life by Luke Lanchester (@Dachande663)
Flying home. More in love.

November 27, 2022
IE – RIP or BRB? by Bruce Lawson (@brucel)
Here’s a YouTube video of a talk I gave for the nerdearla conference, with Spanish subtitles. Basically, it’s about Safari being “the new IE”, and what we at Open Web Advocacy are doing to try to end Apple’s browser ban on iOS and iPads, so consumers can use a more capable browser, and developers can deliver non-hamstrung Progressive Web Apps to iThing users.
Since I gave this talk, the UK Competition and Markets Authority have opened a market investigation into Apple’s iThings browser restriction – read News from UK and EU for more.
November 18, 2022
Reading List 297 by Bruce Lawson (@brucel)
- A Twitter Off Ramp – “A tutorial for getting on Mastodon”. Setting myself up on Mastodon and migrating my “following” list was a doddle thanks to this post, and Vivaldi Social’s ‘Advanced web UI’ is very like Tweetdeck.
- Accessibility Acceptance Criteria – Automatically generate test cases for Web, iOS and Android components
- Mona Sans and Hubot Sans – 2 open source variable fonts from GitHub
- A beginner’s complete guide to form accessibility: the 5 things accessible forms needs and how to fix common errors
- An Introduction to CSS Cascade Layers
- Keeping Your CSS Small: scopes, containers, and other new stuff – really good overview by Tab Atkins
- Significant Improvements for Screen Readers Now in Nightly Firefox – yay!
- Conditionally adaptive CSS. Browser behavior that might improve your performance by Vadim Makeev
- Avoid Messages Under Fields says Adrian Roselli. Auto-complete features in browsers obscure them; On-screen keyboards can obscure them.
- Style a parent element based on its number of children using CSS :has() – I’m not sure why you’d want to, but -hey- you lot can be a bit wild and crazy sometimes.
- aria-label is a code smell – “When I encounter too much, or mis-applied aria-label it makes me take notice. This code smell puts me on alert to investigate things more thoroughly, as it most likely indicates accessibility issues.” says Eric Bailey
- 5 takeaways from screen reader usability interviews
- Mac VoiceOver Testing the Simple Way
- JPEG XL decoding support (image/jxl) in Blink – Lots of disappointment in Chrome’s decision not to ship JPEG XL image format, which many big players want due to its many advantages over other formats
- Browsers, JSON, and FormData – “until we start building our APIs to speak in more than just JSON ”” or we get browsers to speak JSON without requiring JavaScript[2] ”” it’s going to be difficult for progressively-enhanced web pages to gain traction over JavaScript rendered apps.”
- Accessibility ”˜Gaps’ in MVPs – Adrian Roselli grumbles, righteously.
- Is Open Graph Protocol dead? asks Uncle Tezza.
- Apollo 11 Mission Report – “the national objective of landing men on the moon and returning them safely to earth before the end of the decade had been accomplished.” – NASA, November 1969
November 16, 2022
Functional Programming for Under-4s by Andy Wootton (@WooTube)
My grandson has recently learned to count, so I made a set of cards we could ‘play numbers’ with.

We both played. I showed him that you could write ‘maths sentences’ with the ‘and’ and the ‘is’ cards. Next time I visited, he searched in my bag and found the box of numbers. He emptied them out onto the sofa and completely unprompted, ‘wrote’:

I was ‘quite surprised’. We wrote a few more equations using small integers until one added to 8, then he remembered he had a train track that could be made into a figure-of-8 , so ‘Arithmetic Time’ was over but we squeezed in a bit of introductory set theory while tidying the numbers away.
From here on, I’m going to talk about computer programming. I won’t be explaining any jargon I use, so if you want to leave now, I won’t be offended.
I don’t want to take my grandson too far with mathematics in case it conflicts with what he will be taught at school. If schools teach computer programming, it will probably be Python and I gave up on Python.
Instead, I’ve been learning functional programming in the Clojure dialect of Lisp. I’ve been thinking for a while that it woud be much easier to learn functional programming if you didn’t already know imperative programming. There’s a famous text, known as ‘SICP’ or ‘The Wizard Book’ that compares Lisps with magic. What if I took on a sourceror’s apprentice to give me an incentive to learn faster? I need to grab him “to the age of 5”, before the Pythonista get him.
When I think about conventional programming, I make diagrams, and I’ve used Unified Modelling Language (UML) for business analysis, to model ‘data processing’ systems. An interesting feature of LIsps is that process is represented as functions and functions are a special type of data. UML is designed for Object Orient Programming. I haven’t found a way to make it work for Functional Programming (FP.)
So, how can I introduce the ideas of FP to a child who can’t read yet?
There’s a mathematical convention to represent a function as a ‘black-box machine’ with a hopper at the top where you pour in the values and an outlet at the bottom where the answer value flows out. My first thought was to make an ‘add function’ machine but Clojure “treats functions as first-class citizens”, so I’m going to try passing “+” in as a function, along the dotted line labelled f(). Here’s my first prototype machine, passed 3 parameters: 2, 1 and the function +, to configure the black box as an adding machine.

In a Lisp, “2 + 1” is written “(+ 2 1)”.
The ‘parens’ are ‘the black box’.
Now, we’ve made our ‘black box’ an adder, we pass in the integers 2 and 1 and they are transformed by the function into the integer 3.

We can do the same thing in Clojure. Lisp parentheses provide ‘the black box’ and the first argument is the function to use. Other arguments are the numbers to add.
We’ll start the Clojure ‘Read Evaluate Print Loop’ (REPL) now. Clojure now runs well from the command line of a Raspberry Pi 4 or 400 running Raspberry Pi OS.
$ clj
Clojure 1.11.1
user=> (+ 2 1)
3
user=>
Clearly, we have a simple, working Functional Program but another thing about functions is that they can be ‘composed’ into a ‘pipeline’, so we can set up a production line of functional machines, with the second function taking the output of the first function as one of it’s inputs. Using the only function we have so far:
![[5compose–IMG_20221116_135501768-2.jpg]]

In Clojure, we could write that explicitly as a pipeline, to work just like the diagram
(-> (+ 1 2) (+ 1))
4
or use the more conventional Lisp format (start evaluation at the innermost parens)
(+ (+ 1 2) 1)
4
However, unlike the arithmetic “+” operator, the Clojure “+” function can
add up more than 2 numbers, so we didn’t really need to compose the two “+” functions. This single function call would have got the job done:
(+ 1 2 1)
4
SImilarly, we didn’t need to use 2 cardboard black-boxes. We could just pour all the values we wanted adding up into the hopper of the first.
Clojure can handle an infinite number of values, for as long as the computer can, but I don’t think I’ll tell my grandson about infinity until he’s at least 4.
November 14, 2022
In-Flight by Luke Lanchester (@Dachande663)
I am writing this from 32,000 feet above Australia. Modern technology never ceases to amaze.
November 13, 2022
On Scarcity by Graham Lee
It’s called scarcity, and we can’t wait to see what you do with it.
Let’s start with the important bit. I think that over the last year, with acceleration toward the end of the year, I have heard of over 100,000 software engineers losing their jobs in some way. This is a tragedy. Each one of those people is a person, whose livelihood is at the whim of some capricious capitalist or board of same. Some had families, some were working their dream jobs, others had quiet quit and were just paying the bills. Each one of them was let down by a system that values the line going up more than it values their families, their dreams, and their bills.
While I am sad for those people, I am excited for the changes in software engineering that will come in the next decade. Why? Because everything I like about computers came from a place of scarcity in computering, and everything I dislike about computers came from a place of abundance in computering.
The old, waterfall-but-not-quite, measure-twice-and-cut-once approach to project management came from a place of abundance. It’s cheaper, so the idea goes, to have a department of developers sitting around waiting for a functional specification to be completed and signed off by senior management than for them to be writing working software: what if they get it wrong?
The team at Xerox PARC – 50 folks who were just told to get on with it – designed a way of thinking about computers that meant a single child (or, even better, a small group of children) could think about a problem and solve it in a computer themselves. Some of those 50 people also designed the computer they’d do it on, alongside a network and some peripherals.
This begat eXtreme Programming, which burst onto the scene in a time of scarcity (the original .com crash). People had been doing it for a while, but when everyone else ran out of money they started to listen: a small team of maybe 10 folks, left to get on with it, were running rings around departments of 200 people.
Speaking of the .com crash, this is the time when everyone realised how expensive those Oracle and Solaris licenses were. Especially if you compared them with the zero charged for GNU, Linux, and MySQL. The LAMP stack – the beginning of mainstream adoption for GNU and free software in general – is a software scarcity feature.
One of the early (earlier than the .com crash) wins for GNU and the Free Software Foundation was getting NeXT to open up their Objective-C compiler. NeXT was a small team taking off-the-shelf and free components, building a system that rivalled anything Microsoft, AT&T, HP, IBM, Sun, or Digital were doing – and that outlived almost all of them. Remember that the NeXT CEO wouldn’t become a billionaire until his other company released Toy Story, and that NeXT not only did the above, but also defined the first wave of dynamic websites and e-commerce: the best web technology was scarcity web technology.
What’s happened since those stories were enacted is that computerists have collectively forgotten how scarcity breeds innovation. You don’t need to know how 10 folks round a whiteboard can outsmart a 200 engineer department if your department hired 200 engineers _this month_: just put half of them on solving your problems, and half of them on the problems caused by the first half.
Thus we get SAFe and Scrumbut: frameworks for paying lip service to agile development while making sure that each group of 10 folks doesn’t do anything that wasn’t signed off across the other 350 groups of 10 folks.
Thus we get software engineering practices designed to make it easier to add code than to read it: what’s the point of reading the existing code if the one person who wrote it has already been replaced 175 times over, and has moved teams twice?
Thus we get not DevOps, but the DevOps department: why get your developers and ops folks to talk to each other if it’s cheaper to just hire another 200 folks to sit between them?
Thus we get the npm ecosystem: what’s the point of understanding your code if it’s cheaper just to randomly import somebody else’s and hire a team of 30 to deal with the fallout?
Thus we get corporate open source: what’s the point of software freedom when you can hire 100 people to push out code that doesn’t fulfil your needs but makes it easier to hire the next 500 people?
I am sad for the many people whose lives have been upended by the current downturn in the computering economy, but I am also sad for how little gets done within that economy. I look forward to the coming wave of innovation, and the ability to once again do more with less.
November 07, 2022
It’s not about winning by James Nutt (@zerosumjames)
Not everything has to eat the world and the definition of success isn’t always
- be the one true Thing, or at least be the most popular version of The Thing;
- last forever, with infinite growth;
- meet 100% of the use cases of the last Thing, and more.
Life, people, and technology are all more complicated than that.
It’s hard to be attached to something and have it fade away, but that’s part of being a human being and existing in the flow of time. That’s table stakes. I have treasured memories of childhood friends who I haven’t heard from in 20 years. Internet communities that came and went. They weren’t less valuable because they didn’t last forever.
Let a thing just be what it is. So what if it doesn’t pan out the way you expected? If the value you derive from The Thing is reliant on its permanence, you’re setting yourself up for disappointment anyway.
Alternatively, abandon The Thing altogether and, I dunno, go watch a movie or something. The world is your oyster.
No points for figuring out which drama I’m referring to.
October 31, 2022
Explicit help timeouts by James Nutt (@zerosumjames)
swyx wrote an interesting article on how he applied a personal help timeout after letting a problem at work drag on for too long. The help timeout he recommends is something I’ve also recently applied with some of my coworkers, so I thought I’d summarise and plug it here.
There can be a lot of pressure not to ask for help. You might think you’re bothering people, or worse, that they’ll think less of your abilities. It can be useful to counter-balance these thoughts by agreeing an explicit help timeout for your team.
If you’ve been stuck on a task with no progress for x minutes/hours/days, write up your problem and ask the team for help.
There are a few advantages to this:
- It reduces the pressure on an invidivual to decide an appropriate delay. If your team has agreed on one hour, you don’t need to worry about having struggled with a problem for “only” an hour.
- It sets an upper bound on how much time you spend on fruitless struggle. While banging your head against a problem for two weeks can be a valuable learning experience, you need to balance that against delivering results.
- You encourage more rapid sharing of knowledge between team members.
- When you explicitly recognise the reasons people are reluctant to seek help, you lampshade impostor syndrome, reducing its overall power.
Read swyx’s article here: https://www.swyx.io/help-timeouts
October 30, 2022
GeoIP && Docker && GHCR by Luke Lanchester (@Dachande663)
It’s been a very, very long time since I’ve released code to the open web. In fast, the only contributions I’ve done in the last 5 years have been to Chakra and a few other OSS libraries. So, in an attempt to try something new, I recently delved into the world anew.
There have been a few things lately that I wanted to play with:
- Go. I’ve written quite a lot of systems code in Go, but nothing public. I am still terrible at it, but it’s interesting getting things out there.
- Docker. Internally, we’re all Docker but I have yet to actually publish any images.
- Scratch. Still in the docker world, using Go gave me the chance to try a scratch build. No more 500MB images, now I’m getting down to near kilobytes.
- Registries & Actions. And the last docker thing; actually pushing to a registry via automated actions.
- Blogging. I said I’d blog more and so I’m blogging about this!
The app in question is not new, it’s not novel, it’s not even unique in the components it’s using. But it was quick (less than a weekend moring playing around on the sofa), it’s simple (with a minimal surface), and scratches an itch.
GeoIP-lookup is a Go app that uses a local MaxMind City database file, providing a REST API that returns info about an IP address. That’s it.
The app itself is very simple. HTTP, tiny bit of routing, reading databases, and serving responses. GitHub makes it simple to then run an action that generates a new image and pushes this to GHCR. Unfortunately I couldn’t work out what was expected for the signing to work, but that can come later.
The big remaining thing is tests. I’ve got some basic examples in to test the harness, but not much more at the moment. I’ve also learnt how much I miss strict type systems, how much I hate the front-end world, and how good it feels to just get things done and out. Perfect is the enemy of done.
Anyway, it’s live and feels good.
October 28, 2022
Reading List 296 by Bruce Lawson (@brucel)
- How We Uncovered Disparities in Internet Deals – “digital redlining” leads US ISPs to offer “the worst deals to people who are the most in need of affordable prices for high-quality, high-speed internet”: poorer communities of color.
- Element Timing: One true metric to rule them all? – “Sensible defaults, such as Core Web Vitals, are a good start, but one pitfall of standard measures is that they can miss what’s actually most important” says Andy Davies, and he ain’t daft.
- New patterns for amazing apps – Dive into a fantastic collection of new patterns for amazing apps, including clipboard patterns, file patterns, and advanced app patterns. By Thomas Steiner.
- Pop-ups: They’re making a resurgence! – a nice (Chrome-only) experimental declarative way of doing pop-ups. Love this.
- Why we need CSS Speech – “In these times when almost every device and platform is capable of talking to you, you may be surprised to learn that there is no way for authors to design the aural presentation of web content, in the way they can design the visual presentation” writes Leonie “Wedgie” Watters.
- Why We’re Breaking Up with CSS-in-JS by the 2nd most active maintainer of Emotion, a widely-popular CSS-in-JS library for React.
- Library Upgrade Guide: <style> (most CSS-in-JS libs) – React cabal discovers that stylesheets made of CSS are fast and cacheable. “Our preferred solution is to use <link rel=”stylesheet”>”. Who knew?
- Browser Vendors Aim to Heal Developer Pain with Interop 2022
- Handy Tools For Mocking API Requests
- let’s talk about web components says Brad Frost
- When life gives you lemons, write better error messages Wix on the user experience of error messages
- How Chinese citizens use puns to get past internet censors – homophone substitution to evade censorship
- Radix-UI: A gorgeous, accessible color system – “An open-source color system for designing beautiful, accessible websites and apps.” – even if you don’t want to use the React components, there’s some nice colour combos here to “inspire you”.
- An endless collection of accessible color combinations
- Competition regulator needs teeth to curb big tech, MPs say – I can’t help but wonder how the Coalition for a Digital Economy (who are warning MPs against it) reconcile their their work “Regulating with the little guy in mind so startups can innovate safely and compete against the giants” with being supported by Google
- Apple’s App Review Fix Fails to Placate Developers – After bad press about its App Store rules, Apple added a way to challenge app rejections. Creators say projects still get blocked for no good reason.
- Don’t read off the screen – flame-haired Linux lovegod Stuart Langridge has advice for new public speakers
(Last Updated on )
October 20, 2022
Curation over creation by James Nutt (@zerosumjames)
I went to TechMids the last week. One of the talks that had the most immediate impact on me was the talk from Jen Lambourne, one of the authors of Docs for Developers.
One of the ideas contained in the talk was the following:
You might have significantly more impact by curating existing resources than creating new ones.
Like a lot of people, when I started getting into technical writing, I started with a lot of entry level content. Stuff like Ten Tips for a Healthy Codebase and The Early Return Pattern and You. Consequently, there’s a proliferation of 101 level content on blogs like mine, often only lightly re-hashing the source documentation. This isn’t necessarily a bad thing, and I’m definitely not saying that people shouldn’t be writing these articles. You absolutely should be writing this sort of thing if you’re trying to get better at technical writing, and even if there are 100,000 articles on which HTTP verb to use for what, yours could be the one to make it click for someone.
But, I should be asking myself what my actual goal is. If my main priority is to become a better writer with helping people learn being a close second, then I ought to crack on with writing that 100,001st article. If I’m focused specifically on having an impact on learning outcomes, I should consider curating rather than creating.
Maybe the following would be a good start:
- Decide what it is that I wanted to write about.
- Find the strongest existing materials on this topic that I can.
- Decide if there’s something missing from it. Is there any way this can be added, or a supplementary material that can be recommended?
- Decide whether I would have been likely to find these materials if I were having the problem that they address. Is there anything I can do to make them more discoverable?
- Create a signpost. Either on my own site, or by adding to something like the awesome list of awesome lists.
Finally, because I love Ruby and because this is a resource that deserves another signpost, I was recently alerted to The Ruby Learning Center and its resources page. I hope they continue to grow. Hooray for the signpost makers and the librarians.
October 18, 2022
Don’t Read Off The Screen by Stuart Langridge (@sil)
Hear this talk performed (with appropriate background music):
Friends and enemies, attendees of Tech Mids 2022.
Don’t read off the screen.
If I could offer you only one piece of advice for why and how you should speak in public, don’t read off the screen would be it. Reading your slides out is guaranteed to make your talk boring, whereas the rest of my advice has no basis in fact other than my own experience, and the million great people who gave me thoughts on Twitter.
I shall dispense this advice… now.
Every meetup in every town is crying out for speakers, and your voice is valuable. Tell people your story. The way you see things is unique, just like everybody else.
Everybody gets nervous about speaking sometimes. Anybody claiming that they don’t is either lying, or trying to sell you something. If you’re nervous, consider that its a mark of wanting to do a good job.
Don’t start by planning what you want to say. Plan what you want people to hear. Then work backwards from there to find out what to say to make that happen.
You can do this. The audience are on your side.
Find your own style. Take bits and pieces from others and make them something of your own.
Slow down. Breathe. You’re going faster than it feels like you are.
Pee beforehand. If you have a trouser fly, check it.
If someone tells you why you should speak, take their words with a pinch of salt, me included. If they tell you how to speak, take two pinches. But small tips are born of someone else’s bad experience. When they say to use a lapel mic, or drink water, or to have a backup, then listen; they had their bad day so that you didn’t have to.
Don’t put up with rambling opinions from questioners. If they have a comment rather than a question, then they should have applied to do a talk themselves. You were asked to be here. Be proud of that.
Practice. And then practice again, and again. If you think you’ve rehearsed enough, you haven’t.
Speak inclusively, so that none of your audience feels that the talk wasn’t for them.
Making things look unrehearsed takes a lot of rehearsal.
Some people script their talks, some people don’t. Whether you prefer bullet points or a soliloquy is up to you. Whichever you choose, remember: don’t just read out your notes. Your talk is a performance, not a recital.
Nobody knows if you make a mistake. Carry on, and correct it when you can. But keep things simple. Someone drowning in information finds it hard to listen.
Live demos anger the gods of speaking. If you can avoid a live demo, do so. Record it in advance, or prep it so that it looks live. Nobody minds at all.
Don’t do a talk only once.
Acting can be useful, if that’s the style you like. Improv classes, stage presence, how you stand and what you do with your hands, all of this can be taught. But put your shoulders back and you’ve got about half of it.
Carry your own HDMI adapter and have a backup copy of your talk. Your technology will betray you if it gets a chance.
Record your practices and watch yourself back. It can be a humbling experience, but you are your own best teacher, if you’re willing to listen.
Try to have a star moment: something that people will remember about what you said and the way you said it. Whether that’s a surprising truth or an excellent joke or a weird gimmick, your goal is to have people walk away remembering what you said. Help them to do that.
Now, go do talks. I’m Stuart Langridge, and you aren’t. So do your talk, your way.
But trust me: don’t read off the screen.
October 15, 2022
Starting by Luke Lanchester (@Dachande663)
I’m going to start blogging again. No reason why, no reason why-not. A lot has happened in the last twelve months; head, wife, job, decisions. Expect lots of random things.
For now, I’m in Saundersfoot enjoying the culmination of the World Rowing Beach Sprint Finals. Take care.

October 11, 2022
Inclusive name inputs – because not everyone is called Chad Pancreas by Bruce Lawson (@brucel)
Recently, “Stinky” Taylar and I were evaluating some third party software for accessibility. One of the problems was their sign-up form.

This simple two-field form has at least three problems:
- The “first name” must be two characters or more.
- “First name” and “last Name” aren’t defined; are they “given name” and “family name”?
- “Last name” is mandatory
U Nagaharu was a Korean-Japanese botanist. Why shouldn’t he sign up to your site? In Burmese “U” is a also a given name: painter Paw U Thet, actor Win U, historian Thant Myint U, and politicians Ba U and Tin Aung Myint U have this name. Note that for these Burmese people, their given names are not the “first name”; many Asian languages put the family name first, so their “first name” is actually their surname, not their given name.
Many Afghans have no surname. It is also common to have no surname in Bhutan, Indonesia, Myanmar, Tibet, Mongolia and South India. Javanese names traditionally are mononymic, especially among people of older generations, for example, ex-presidents Suharno and Sukarno, which are their full legal names.
Many other people go by one name. Can you imagine how grumpy Madonna, Bono and Cher would be if they tried to sign up to buy your widgets but they couldn’t? Actually, you don’t need to imagine, because I asked Stable Diffusion to draw “Bono, Madonna and Cher, looking very angrily at you”:

Imagine how angry your boss would be if these multi-millionaires couldn’t buy your thingie because you coded your web forms without questioning falsehoods programmers believe about names.
How did this happen? It’s pretty certain that these development teams don’t have an irrational hatred of Indonesians, South Indians, Koreans and Burmese people. It is, however, much more likely they despise Cher, Madonna, and Bono (whose name is “O’Nob” backwards).
What is far more likely is that no-one on these teams is from South East Asia, so they simply didn’t know that not all the world has American-style names. (Many mononymic immigrants to the USA might actually have been “given” or inherited the names “LNU” or “FNU”, which are acronyms of “Last name unknown” or “First name unknown”.)
This is why there is a strong and statistically significant correlation between the diversity of management teams and overall innovation and why companies with more diverse workforces perform better financially.
The W3C has a comprehensive look at Personal names around the world, written by their internationalisation expert, Richard Ishida. I prefer to ask for “Given name”, with no minimum or maximum length, and optional “family name or other names”.
So take another look at your name input fields. Remember, not everyone has a name like “Chad Pancreas” or “Bobbii-Jo Musteemuff”.
(Last Updated on )
October 06, 2022
Appearance: Bootstrapped.fm 232 by Marc Jenkins (@marcjenkins)
Steve McLeod invited me on his podcast, Bootstrapped.fm, to discuss how I run a small web studio called 16by9.
Marc and I talk about what its like to start and build up this type of company, and how, with some careful thinking, you can avoid letting your business become something you never wanted it to be.
You can listen here.
I haven’t recorded many podcasts before but this was a blast. Massive thanks to Steve for inviting me on.
September 30, 2022
Reading List 295 by Bruce Lawson (@brucel)
- Link of the Week: Learn HTML – “This HTML course for web developers provides a solid overview for developers, from novice to expert level HTML”. Wen if you think you know it all cuz you’re a Full-Stack Ninja, read this. It will make your React/ Angular/ Vue/ Svelte apps better. By Estelle Weyl.
- Also, Learn Accessibility. Please!
- Accessibility Features – “Almost half of all people with a mobile phone use accessibility features. Much more than you would expect, right? In our survey of millions of iOS and Android users, we looked at which accessibility features are enabled.”
- What’s new in WCAG 2.2? by Hidde de Vries
- Better accessible names – “OK, you’ve added an accessible name to your control. Maybe you’ve used aria-label, <label> or some other way to name a control. Now you wonder: what makes a name good, effective or useful?” Another one from Hidde.
- How Fast Is Your Web App? How to Test Page Transition Performance – Scott Jehl on how to test a website’s post-load navigation speed in WebPageTest. This process is something you can use on any kind of website, but may be particularly handy for testing single-page web apps that tend to handle page navigations on the client-side.
- Why haven’t PWAs killed native apps yet?
- Outdated vs. Complete – “In defense of apps that don’t need updates”. Apple now requires devs to update perfectly functional apps for no reason, so you have to keep paying for developer membership and waste time recompiling against a massive Xcode update.
- It’s Mid-2022 and Browsers (Mostly Safari) Still Break Accessibility via Display Properties by Adrian Roselli
- What to Know About Accessible PDFs From Microsoft Word and Google Docs = TL;DR: PDFs generated by exporting from Word are more accessible than those from Google Docs
- Shrinking APKs, growing installs. How your app’s APK size impacts install conversion rates – “smaller APK sizes correlate with higher install conversion rates, with an even larger impact on conversion rates for users in emerging markets” (from 2017, but I bet it holds true now)
- Will Serving Real HTML Content Make A Website Faster? Let’s Experiment! – TL;DR: “serving useful HTML up-front faster than client-side generated HTML–often by a lot.” Who knew????!
- DiffusionBee – install and run the Stable Diffusion text-to-image AI on Mac with a GUI (and some ideas of how to prompt it)
- QR Code development story (and the spec)
September 26, 2022
Housekeeping by Marc Jenkins (@marcjenkins)
I’ve made a few content updates over the past week or so:
- Updated my /now page with what I’m doing now
- Added a few new applications to my /uses page
- Added the books I’ve read recently to my reading page
- Added a new photography page where I’ll be uploading some of my favourite photos
A few months back I also created an Unoffice Hours page. It’s one of the highlights of my week. If you fancy saying hello, book a call.
September 20, 2022
Client experiences and expectations by Marc Jenkins (@marcjenkins)
I’ve been documenting the various processes in my business over the past few months. This week, I’ve been thinking about the process of on-boarding new clients.
How do I ensure we’re a good fit? How do I go beyond what they’re asking for and really understand what they’re after? How do we transition from “we’ve never spoken before” to “I trust you enough to put down a deposit for this project”?
There’s another question that has occurred to me lately: have they commissioned a website before? And if so, how does this impact the expectations they have?
When I started building client websites – some 18 years ago(!) – the majority of people I worked with had never commissioned a website before.
These days when I speak to clients, they’re often on the 4th or 5th redesign of their website. Even if I’m asked to build a brand new website, most of the people I speak to have been through the process of having a website built numerous times before.
In other words: early in my career, most of the people I built websites for didn’t have any preconceived notions of how a website should be built or the process one goes through to create one. These days, they do.
Sometimes they have good experiences and work with talented freelancers or teams. But often I hear horror stories of how they’ve been burned through poor project planning or projects taking longer than expected and going over budget.
I’ve found it worthwhile to ask about these experiences. The quicker I can identify their previous experience and expectations, especially if they’re negative, the quicker I can reassure them that there’s a proven process that we’ll follow.
September 08, 2022
Transcendence by Graham Lee
I was at the RSE conference in Newcastle, along with many people whom I have met, worked with, and enjoyed talking to in the past. Many more people whom I have met, worked with, and enjoyed talking to in the past were at an entirely different conference in Aberystwyth, and I am disappointed to have missed out there.
One of the keynote speakers at RSEcon22, Marlene Manghami, talked about the idea of transcendence through community membership. They cited evidence that fans of soccer teams go through the same hormonal shifts at the same intensity during the match as the players themselves. Effectively the fans are on the pitch, playing the game, feeling the same feelings as their comrades on the team, even though they are in the stands or even at home watching on TV.
I do not know that I have felt that sense of transcendence, and believe I am probably missing out both on strong emotional connections with others and on an ability to contribute effectively to society (to a society, to any society) by lacking the strong motivation that comes from knowing that making other people happier makes me happier, because I am with them.
August 31, 2022
Farmbound, or how I built an app in 2022 by Stuart Langridge (@sil)
So, I made a game. It’s called Farmbound. It’s a puzzle; you get a sequence of farm things — seeds, crops, knives, water — and they combine to make better items and to give you points. Knives next to crops and fields continually harvest them for points; seeds combine to make crops which combine to make fields; water and manure grow a seed into a crop and a crop into a field. Think of it like a cross between a match-3 game and Little Alchemy. The wrinkle is that the sequence of items you get is the same for the whole day: if you play again, you’ll get the same things in the same order, so you can learn and refine your strategy. It’s rather fun: give it a try.

It’s a web app. Works for everyone. And I thought it would be useful to explain why it is, why I think that’s the way to do things, and some of the interesting parts of building an app for everyone to play which is delivered over the web rather than via app stores and downloads.
Why’s it a web app and not a platform-specific native app?
Well, there are a bunch of practical reasons. You get completely immediate play with a web app; someone taps on a share link, and they’re playing. No installation, no platform detection, it Just Works (to coin a phrase which nobody has ever used before about apps ever in the history of technology). And for something like this, an app with platform-specific code isn’t needed: sure, if you’re talking to some hardware devices, or doing low-level device fiddling or operating system integration, you might need to build and deliver something separately to each platform. But Farmbound is not that. There is nothing that Farmbound needs that requires a native app (well, nearly nothing, and see later). So it isn’t one.
There are some benefits for me as the developer, too. Such things are less important; the people playing are the important ones. But if I can make things nicer for myself without making them worse for players, then I’m going to do it. Obviously there’s only one codebase. (For platform-specific apps that can be alleviated a little with cross-platform frameworks, some of which are OK these days.) One still needs to test across platforms, though, so that’s not a huge benefit. On the other hand, I don’t have to pay extra to distribute it (beyond it being on my website, which I’d be paying for anyway), and importantly I don’t have to keep paying in order to keep my game available for ever. There’s no annual tithe required. There’s no review process. I also get support for minority platforms by publishing on the web… and I’m not really talking about something in use by a half-dozen people here. I’m talking about desktop computers. How many people building a native app, even a relatively simple puzzle game like this, make a build for iOS and Android and Windows and Mac and Linux? Not many. The web gets me all that for minimal extra work, and if someone on FreeBSD or KaiOS wants to play, they can, as long as they’ve got a modern browser. (People saying “what about those without modern browsers”… see below.)
But from a less practical and more philosophical point of view… I shouldn’t need to build a platform-specific native app to make a game like this. We want a world where anyone can build and publish an app without having to ask permission, right? I shouldn’t need to go through a review process or be beholden to someone else deciding whether to publish my game. The web works. Would Wordle have become so popular if you had to download a Windows app or wait for review before an update happened? I doubt it. I used to say that if you’re building something complex like Photoshop then maybe go native, but in a world with Figma in it, that maybe doesn’t apply any more, and so Adobe listened to that and now Photoshop is on the web. Give people a thing which doesn’t need installation, gets them playing straight away, and works everywhere? Sounds good to me. Farmbound’s a web app.
Why’s it not got its own domain, then, if it’s on the web?
Farmbound shouldn’t need its own domain, I don’t think. If people find out about it, it’ll likely be by shared links showing off how someone else did, which means they click the link. If it’s popular then it’ll be top hit for its own name (if it isn’t, the Google people need to have a serious talk with themselves), and if it isn’t popular then it doesn’t matter. And, like native app building, I don’t really want to be on the hook forever for paying for a domain; sure, it’s not much money, but it’s still annoying that I’m paying for a couple of ideas that I had a decade ago and which nobody cares about any more. I can’t drop them, because of course cool URIs don’t change, and I didn’t want to be thinking a decade from now, do I still need to pay for this?
In slightly more ego-driven terms, it being on my website means I get the credit, too. Plus, I quite like seeing things that are part of an existing site. This is what drove the (admittedly hipster-ish) rise of “tilde sites” again a few years ago; a bit of nostalgia for a long time ago. Fortunately, I’ve also got Cloudflare in front of my site, which alleviates worries I might have had about it dying under load, although check back with me again if that happens to see if it turns out to be true or not. (Also, I’m considering alternatives to Cloudflare at the moment too.)
So what was annoying and a problem when building an app on the web?
Architecture
Firstly, I separated the front and back ends and deployed them in different places. I’m not all that confident that my hosted site can cope with being hammered, if I’m honest. This is alleviated somewhat by cloud caching, and hopefully quite a bit more by having a service worker in place which caches almost everything (although see below about that), but a lot of this decision was driven by not wanting to incur a server hit for every visitor every time, as much as possible. This drove at least some of the architectural decisions. The front end is on my site and is plain HTML, CSS, and JavaScript. The back end is not touched when starting the game; it’s only touched when you finish a game, in order to submit your score and get back the best score that day to see if you beat that. That back end is written in Deno, and is hosted on fly.io, who seem pretty cool. (I did look at Deno Deploy, but they don’t do permanent storage.)
Part of the reason the back end is a bit of extra work is that it verifies your submitted game to check you aren’t cheating and lying about your score. This required me to completely reimplement the game code in Deno. Now, you may be saying “what? the front end game code is in JavaScript and so is the back end? why don’t they share a library?” and the answer is, because I didn’t think of it. So I wrote the front end first and didn’t separate out the core game management from all the “animate this stuff with CSS” bits, because it was a fun weekend project done as a proof of concept. Once I got a bit further into it and realised that I should have done that… I didn’t wanna, because that would have sucked all the fun out of the project like a vampire and meant that I’d have never done it. So, take this as a lesson: think about whether you want a thing to be popular up front. Not that you’ll listen to this advice, because I never do either.
Similarly, this means that there’s less in the way of analytics, so I don’t get information about users, or real-time monitoring of popularity. This is because I did not want to add Google Analytics or similar things. No personal data about you ever leaves your device. You’ll have noticed that there’s no awful pop-up cookie consent dialogue; this is because I don’t need one, because I don’t collect any analytics data about players at all! Guess what, people who find those dialogues annoying (i.e., everyone?) You can tell companies to stop collecting data about you and then they won’t need an annoying dialogue! And when they say no… well, then you’ll have learned something about how they view you as customers, perhaps. Similarly, when scores are submitted, there’s no personal information that goes with them. I don’t even know whether two scores were submitted by the same person; there’s no unique ID per person or per device or anything. (Technically, the IP is submitted to the server, of course, but I don’t record it or use it; you’ll have to take my word for that.)
This architecture split also partially explains why the game’s JavaScript-dependent. I know, right? Me, the bloke who wrote “Everyone has JavaScript, right?“, building a thing which requires JS to run? What am I doing? Well, honestly, I don’t want to incur repeated server hits is the thing. For a real project, something which was critical, then I absolutely would do that; I have the server game simulation, and I could relatively easily have the server pass back a game state along with the HTML which was then submitted. The page is set up to work this way: the board is a <form>, the things you click on are <button>s, and so on. But I’m frightened of it getting really popular and then me getting a large bill for cloud hosting. In this particular situation and this particular project, I’d rather the thing die than do that. That’s not how I’d build something more critical, but… Farmbound’s a puzzle game. I’m OK with it not working, and if I turn out to be wrong about that, I can change that implementation relatively quickly without it being a big problem. It’s not architected in a JS-dependent way; it’s just progressively enhanced that way.
iOS browser
I had a certain amount of hassle from iOS Safari. Some of this is pretty common — how do I stop a double-tap zooming in? How do I stop the page overscrolling? — but most of the “fixes” are a combination of experimentation, cargo culting ideas off Stack Overflow, and something akin to wishing on a star. That’s all pretty irritating, although Safari is hardly alone in this. But there is a separate thing which is iOS Safari specific, which is this: I can’t sensibly present an “add this to your home screen” hint in iOS browsers other than Safari itself. In iOS Safari, I can show a little hint to help people know that they can add Farmbound to their home screen (which of course is delayed until a second game is begun and then goes away for a month if you dismiss it, because hassling your own players is a foolish thing to do). But in non Safari iOS browsers (which, lest we forget, are still Safari under the covers; see Open Web Advocacy if this is a surprise to you or if you don’t like it), I can’t sensibly present that hint. Because those non-Safari iOS browsers aren’t allowed to add web apps to your home screen at all. I can’t even give people a convenient tap to open Farmbound in iOS Safari where they can add the app to their home screen, because there’s no way of doing that. So, apologies, Chrome iOS or Firefox iOS users and others: you’ll have to open Farmbound in Safari itself if you want an easy way to come back every day. At least for now.
Service workers
And finally, and honestly most annoyingly, the service worker.
Building and debugging and testing a service worker is still so hard. Working out why this page is cached, or why it isn’t cached, or why it isn’t loading, is incredibly baffling and infuriating still, and I just don’t get it. I tried using “workbox”, but that doesn’t actually explain how to use it properly. In particular, for this use case, a completely static unchanging site, what I want is “cache this actual page and all its dependencies forever, unless there’s a change”. However, all the docs assume that I’m building an “app shell” which then uses fetch() to get data off the server repeatedly, and so won’t shut up about “network first” and “cache first, falling back” and so on rather than the “just cache it all because it’s static, and then shut up” methodology. And getting insight into why a thing loaded or didn’t is really hard! Sure, also having Cloudflare caching stuff and my browser caching stuff as well really doesn’t help here. But I am not even slightly convinced that I’ve done all this correctly, and I don’t really know how to be better. It’s too hard, still.
Conclusion
So that’s why Farmbound is the way it is. It’s been interesting to create, and I am very grateful to the Elite Farmbound Testing Team for a great deal of feedback and helping me refine the idea and the play: lots of love to popey, Roger, Simon, Martin, and Mark, as well as Handy Matt and my mum!
There are still some things I might do in the future (achievements? maybe), and I might change the design (I’m not great at visual design, as you can tell), and I really wish that I could have done all the animations with Shared Element Transitions because it would have been 312 times easier than the way I did it (a bunch of them add generated content and then web-animations-api move the ::before around, which I thought was quite neat but is also daft by comparison with SET). But I’m pleased with the implementation, and most importantly it’s actually fun to play. Getting over a thousand points is really good (although sometimes impossible, on some days), and I don’t really think the best strategies have been worked out yet. Is it better to make fields and tractors, or not go that far? Is water a boon or an annoyance? I’d be interested in your thoughts. Go play Farmbound, and share your results with me on Twitter!
August 19, 2022
Reading List 294 by Bruce Lawson (@brucel)
- TikTok’s In-App Browser Reportedly Capable of Monitoring Anything You Type – “TikTok’s custom in-app browser on iOS reportedly injects JavaScript code into external websites that allows TikTok to monitor “all keyboard inputs and taps” while a user is interacting with a given website” – IABs are a boil on the bum of the Web.
- Let websites framebust out of native apps – “When a native app embeds a website via a webview, the native app has control over that page. Yes, even if it’s on a domain that the native app doesn’t control (!). This means the native app can inject whatever JavaScript it likes into any website that’s viewed in the webview”
- The point of a dashboard isn’t to use a dashboard – “A dashboard isn’t there to be used. It is there to prove that the data are easily accessible, comparable, and trackable. Only once that is done can they be actionable. Trapped data is useless data.” opines Uncle Tezza.
- New macOS 12.5.1 and iOS 15.6.1 updates patch “actively exploited” vulnerabilities “CVE-2022-32893, is a WebKit bug that allows for arbitrary code execution via “maliciously crafted web content” – update your iOS. Because of the #appleBrowserBan, every browser on iThings is compromised, because Apple requires them all to use its WebKit.
- Facebook gave police their private data. Now, this duo face abortion charges – “Private messages discussing how to obtain abortion pills were given to police by Facebook.”
- Browsers Are Back in the Antitrust Hot Seat – “Google and Apple control more than 80% of market through Chrome and Safari, raising questions among regulators and competitors” (WSJ)
August 18, 2022
Debut album: “Calling For The Moon” by Bruce Lawson (@brucel)
My debut album is out, featuring 10 songs written while I was living in Thailand, India and Turkey. It’s quite a jumble of genres, as I like lots of different types of music, and not everyone will like it – I write the songs I want to hear, not for other people’s appetites.

You can buy it on Bandcamp for £2 or more, or (if you’re a cheapskate) you can stream it on Spotify or Apple Music. I am available for autographing breasts or buttocks.
(Last Updated on )
August 17, 2022
The Image Model by Graham Lee
I was reflecting on things that I know now, a couple of decades in to my career, that I wish I had been told at the beginning. Many things came to mind, but the most immediate from a technological perspective was Smalltalk’s image model.
It’s not even the technology of the Smalltalk image that’s relevant, but the model of thinking that works well with it. In Smalltalk, there are two (three) important files for a given machine: the VM is the machine that can run Smalltalk; the image is a snapshot of all of the Smalltalk objects on the machine(; and the sources are the source code for the classes and methods in that image).
This has weird implications for how you work that differ greatly from “compile this text stream” or “interpret this text stream” programming environments. People who have used the ENVY/Developer tool generally seem to wax lyrical and wonder why it was never reinvented, like the rest of software engineering is the beach with the ruins of the Statue of Liberty poking out from the end of the Planet of the Apes. But the bit I wish I had been told about: the image model puts the “personal” in “personal computer” as far as programming is concerned. Every piece of software you write is part of your image: a peer of the rest of the software you wrote, of the software that other people wrote that you added, and of the software that was already there when you first booted the machine.
I wish I had been told to think like that: that each tool or project is not a separate tool or project, but a cumulative addition to the image. To keep everything I wrote, so that the next time I needed something I might not need to write it. To make sure, when using new things, that I could integrate them with the image (it didn’t exist at the time, but TruffleSQUEAK is very much this idea). To give up asking “how can I write software to solve this problem”, and to start asking “how can I solve this problem with software, writing some if necessary”?
It would be the difference between twenty of years of experience and one year of experience, twenty times over.
August 16, 2022
Introduction to desktop screen readers – the movie! by Bruce Lawson (@brucel)
My Work Bezzie “Stinky” Taylar Bouwmeester and I take you on a wild, roller-coaster ride through the magical world of desktop screen readers. Who uses them? How they can help if developers use semantic HTML? How you can test your work with a desktop screenreader? (Parental discretion advised).
August 15, 2022
Making accessible DocuSign forms by Bruce Lawson (@brucel)
Last week I observed a blind screen reader user attempting to complete a legal document that had been emailed to them via DocuSign. This is a service that takes a PDF document, and turns it into a web page for a user to fill in and put an electronic signature to. The user struggled to complete a form because none of the fields had data labels, so whereas I could see the form said “Name”, “Address”, “Phone number”, “I accept the terms and conditions”, the blind user just heard “input, required. checkbox, required”.
Ordinarily, I’d dismiss the product as inaccessible, but DocuSign’s accessibility statement says “DocuSign’s eSignature Signing Experience conforms to and continually tests for GovernmentSection 508 and WCAG 2.1 Level AA compliance. These products are accessible to our clients’ customers by supporting Common screen readers” and had been audited by The Paciello Group, whom I trust.
So I set about experimenting by signing up for a free trial and authoring a test document, using Google Docs and exporting as a PDF. I then imported this into DocuSign and began adding fields to it. I noticed that each input has a set of properties (required, optional etc) and one of these is ‘Data Label’. Aha! HTML fields have a <label> associated with them (or should do), so I duplicated the text and sent the form to my Work Bezzie, Stinky Taylar, to test.

No joy. The labels were not announced. (It seems that the ‘data label’ field actually becomes a column header in the management report screen.) So I set about adding text into the other fields, and through trial and error discovered how to force the front-end to have audible data labels:
- Text fields should have the visible label duplicated in the ‘tooltip’ field.
- Radio buttons and checkboxes: type the question (eg, what would be the <legend>) into the ‘group tooltip’ field.
- Each individual checkbox or radio button’s label should be entered into the “checkbox/ radio button value” field.
I think DocuSign is missing a trick here. Given the importance of input labels for screen readers, a DocuSign author should be prompted for this information, with an explanation of why it’s needed. I don’t think it would be too hard to find the text immediately preceeding the field (or immediately following it on the same line, in the case of radio/ checkboxes) and prefilling the prompt, as that’s likely to be the relevant label. Why go to all the effort to make an accessible product, then make it so easy for your customers to get it wrong?
Another niggle: on the front end, there is an invisible link that is visually revealed when tabbed to, and says “Press enter or use the screen reader to access your document”. However, the tester I observed had navigated directly to the PDF document via headings, and hadn’t tabbed to the hidden link. The ‘screenreader mode’ seemed visually identical to the default ‘hunt for help, cripples!” mode, so why not just have the accessible mode as the default?
All in all, it’s a good product, let down by poor usability and a ‘bolt-on’ approach. And, as we all know, built-in beats bolt-on. Bigly.
August 05, 2022
Reading List 293 by Bruce Lawson (@brucel)
- Northern Bloke talking about CSS on YouTube link of the month: Be the browser’s mentor, not its micromanager – Andy Bell on how we can hint the browser, rather than micromanage it by leaning into progressive enhancement, CSS layout, fluid type & space and modern CSS capabilities to build resilient front-ends that look great for everyone, regardless of their device, connection speed or context
- Focus management still matters – Sarah Higley takes us on a magical mystery tour of
sequential-focus-navigation-starting-point - Date and Time Pickers for All “the release of the React Aria and React Spectrum date and time picker components… a full suite of fully featured components and hooks including calendars, date and time fields, and range pickers, all with a focus on internationalization and accessibility. It also includes @internationalized/date, a brand new framework-agnostic library for locale-aware date and time manipulation … All of our date and time picker components have been tested across desktop and mobile devices, and with many different input methods including mouse, touch, and keyboard. We have worked hard to ensure screen reader announcements are clear and consistent.
- Replace the outline algorithm with one based on heading levels – The HTML spec now reflects what actually happens in browsers, rather than what we wish happens. The outlining algorithm allowed what would be effectively a generic heading element, with a level corresponding to its nesting in sectioning elements. But no browser implemented it, so the spec reverts to reality so developers didn’t mistakenly believe it is possible.
- What is the best way to mark up an exclusive button group? by Lea Verou
- Perceived affordances and the functionality mismatch – a companion piece by Léonie Watson
- JSX in the browser by Chris Ferdinandi
- An Accessibility-First Approach To Chart Visual Design
- Bunny Fonts “is an open-source, privacy-first web font platform designed to put privacy back into the internet…with a zero-tracking and no-logging policy”, so an alternative to Google Fonts
- Font Subsetting Strategies: Content-Based vs Alphabetical – “Font subsetting allows you to split a font’s characters (letters, numbers, symbols, etc.) into separate files so your visitors only download what they need. There are two main subsetting strategies that have different advantages depending on the type of site you’re building.”
- Dragon versions and meeting accessibility guidelines “Dragon responds to the visible text label, the accessible name and the “name” attribute … Microsoft are in the process of buying Nuance, and it’s a measure of how unpopular Nuance is that most people think that a Microsoft takeover would be a very good thing.”
- The Surprising Truth About Pixels and Accessibility – “Should I use pixels or ems/rems?!”
by Josh W. Comeau - Android accessibility: roles and TalkBack by Graeme Coleman (Tetralogical)
- Three Steps To Start Practicing Inclusive Product Development – “Product teams aren’t intentionally designing products that exclude users, but a lack of team diversity, specialized knowledge and access to feedback from people with disabilities results in users being left behind.”
- Court OKs billion-dollar Play Store gouging suit against Google
- The hidden history of screen readers – “For decades, blind programmers have been creating the tools their community needs”
- Introducing: Emoji Kitchen


 – Jennifer Daniel, the chair of the Unicode Consortium’s emoji subcommittee, asks “How can we reconcile the rapid ever changing way we communicate online with the formal methodical process of a standards body that digitizes written languages?” and introduces the Poopnado emoji
– Jennifer Daniel, the chair of the Unicode Consortium’s emoji subcommittee, asks “How can we reconcile the rapid ever changing way we communicate online with the formal methodical process of a standards body that digitizes written languages?” and introduces the Poopnado emoji
Authors
All the Birmingham-flavoured tech content on this page is supplied by local bloggers:
Want your blog's content featured here?
For information on submitting your blog for inclusion on this list, visit our blog submission page on Birmingham.IO.